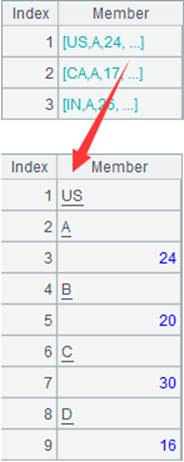
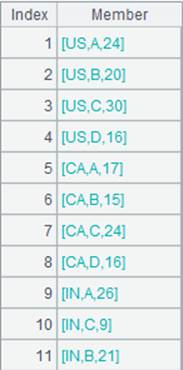
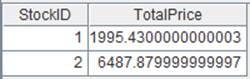
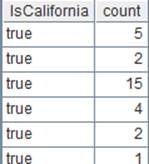
T.groups()
Description:
Group records in a pseudo table.
Syntax:
T. groups(x:F,…;y:G…;n)
Note:
The function groups records in a pseudo table by expression x, sorts result by the grouping field, and perform an aggregate operation on each group.
This creates a new table sequence consisting of fields F,...G,… and sorted by the grouping field x. G field gets values by computing aggregate function y on each group.
Option:
|
@n |
The value of grouping expression is group number used to locate the group; you can use n to specify the number of groups and generate corresponding number of zones first |
|
@u |
Do not sort the result set by the grouping expression; it doesn’t work with @n |
|
@o |
Compare each record only with its neighboring record to group, which is equivalent to the merge operation, and won’t sort the result set |
|
@i |
With this option, the function only has one parameter x that is a Boolean expression; start a new group if its result is true |
|
@h |
Used over a grouped table with each group ordered to speed up grouping |
|
@b |
Enable returning a result set containing aggregates only without group-level data |
|
@v |
Store the composite table in the column-wise format when loading it the first time, which helps to increase performance |
Parameter:
|
T |
A pseudo table |
|
x |
Grouping expression; if omitting parameters x:F, aggregate the whole set; in this case, the semicolon “;” must not be omitted |
|
F |
Field name in the result table sequence |
|
y |
An aggregate function on T, which only supports sum/count/max/min/top/avg/iterate/concat/var; when the function works with iterate(x,a;Gi,…) function, the latter’s parameter Gi should be omitted |
|
G |
Aggregate field name in the result table sequence |
|
n |
The specified maximum number of groups; stop executing the function when the number of data groups is bigger than n to prevent memory overflow; the parameter is used in scenarios when it is predicted that data will be divided into a large number of groups that are greater than n |
Return value:
Pseudo table
Example:
|
|
A |
|
|
1 |
=create(file).record(["D:/file/pseudo/empT.ctx"]) |
|
|
2 |
=pseudo(A1) |
Generate a pseudo table. |
|
3 |
=A2.groups(DEPT:dept;avg(SALARY):AVG_SALARY) |
Group records in A2’s pseudo table by DEPT field, calculate average of SALARY in each group – which is the aggregate method, and return result as a table sequence made up of dept field, and AVG_SALARY field and sorted by dept.
|
|
4 |
=A2.groups@n(if(GENDER=="F",1,2):GenderGroup;avg(SALARY):AVG_SALARY) |
Devide recrods of A2’s pseudo table into two groups according to whether GENDER is F, and calculate average SALARY in each group.
|
|
5 |
=A2.groups@u(DEPT:dept;avg(SALARY):AVG_SALARY) |
With @u option, the grouping result won’t be sorted.
|
|
6 |
=A2.groups@o(DEPT:dept;avg(SALARY):AVG_SALARY) |
Withe @o option, compare each record with its next neighbor and won’t sort the result set.
|
|
7 |
=A2.groups@i(GENDER=="M":isMAN;count(EID):Count) |
Start a new group if the current record meets the condition GENDER=="M".
|
|
8 |
=A2.groups@b(DEPT:dept;avg(SALARY):AVG_SALARY) |
With @b option, return only a column of aggregates without group data.
|