regex()
Here’s how to use regex() function.
s. regex()
Description:
Match a string with the regular expression.
Syntax:
s.regex(rs,rpls)
Note:
The function matches string s with the regular expression rs, replaces the first matched character with string rpls, and returns the string after replacement.
It returns a sequence consisting of matching strings when parameter rpls is absent, and null when the matching fails.
Parameter:
|
s |
A string. |
|
rs |
Regular expression. |
|
rpls |
A string. |
Option:
|
@c |
Case insensitive. |
|
@u |
Use Unicode to match. |
|
@a |
Replace all matching characters. |
|
@w |
Find whether the regular expression matches with the whole string. |
|
@p |
Parse the result numeric string into a number. |
Return value:
Sequence/String/Numeric value
Example:
|
|
A |
|
|
1 |
4,23,a,test |
|
|
2 |
a,D |
|
|
3 |
W,F |
|
|
4 |
=A1.regex("(\\d),([0-9]*),([a-z]),([a-z]*)") |
|
|
5 |
=A2.regex@c("([a-z]),([a-z])") |
With @c option, it is case insensitive. |
|
6 |
=A2.regex("([a-z]),([a-z])") |
Return null because they don’t match. |
|
7 |
=A3.regex@u("(\\u0057),(\\u0046)") |
[W,F]; Use unicode to match. |
|
8 |
=A1.regex("([0-9])","hello") |
hello,23,a,test. |
|
9 |
=A1.regex@a("([0-9])","hello") |
hello,hellohello,a,test. |
|
10 |
="123abc".regex("[0-9]a") |
123abc. |
|
11 |
="123abc".regex@w("[0-9]a") |
Use @w option to find whether the whole string matches and return null. |
|
12 |
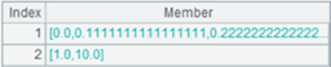
="9,20,hello,6.269".regex("([0-9.]+)") |
Return a sequence of strings:
|
|
13 |
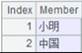
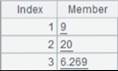
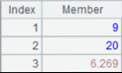
="9,20,hello,6.269".regex@p("([0-9.]+)") |
Parse result numeric strings into numeric values:
|

Related function:
A. regex()
Description:
Match members in a string sequence with the regular expression.
Syntax:
|
A.regex(rs,Fi) |
If no extracting item is specified in rs, match field Fi of the string with rs based on data type. Then return the new record sequence after record sequence A is filtered. Use the current record to match with rs if omitting Fi. |
|
A.regex(rs;Fi,…) |
If one or more extracting items are specified in rs, split the string members of sequence A according to them, and return the results as a table sequence whose fields are Fi. |
Note:
The function matches the members of string type in the sequence A with the regular expression rs.
The results will be merged into a table sequence whose fields are Fi for returning.
Parameter:
|
A |
A sequence or a record sequence whose members are strings. |
|
rs |
Regular expressions. The extracting items are specified sub-regular expressions which are separated from each other by separators and each is surrounded with the parentheses. They will match the fields in sequence. For example, "(.*),(a.*)" are two extracting items separated by a comma. |
|
Fi |
Resulting field names of string type. |
Option:
|
@c |
Case insensitive. |
|
@u |
Use Unicode to match. |
|
@p |
Parse the result numeric string into a number. |
Return value:
Table sequence
Example:
|
|
A |
|
|
1 |
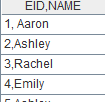
=demo.query("select NAME,SURNAME from EMPLOYEE") |
|
|
2 |
=A1.(~.array().concat@c()) |
Convert to a sequence of strings. |
|
3 |
=A2.regex("A.*") |
By default, use current record to match with rs if omitting Fi. |
|
4 |
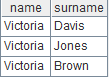
=A2.regex("(V.*),(.*)";name,surname) |
Match members of A2 with the regular expressions and return a table sequence. |
|
5 |
=file("D:\\a.txt").import@ts() |
|
|
6 |
=A5.(#1).regex@c("(.*),(a.*)";id,name) |
Match names that start with a or A. |
|
7 |
=file("D:\\c.txt":"UTF-8").import@ts() |
|
|
8 |
=A7.(~.array().concat@c()) |
|
|
9 |
=A8.regex@u("(\\u9500\\u552e\\u90e8),(.*)";SalesDep,EmployeeName) |
Use Unicode to match the Sales Dep. |
|
10 |
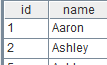
=A1.regex("V.*",NAME) |
Without an extracting item, match the regular expression rs with the string type Fi field. |
|
11 |
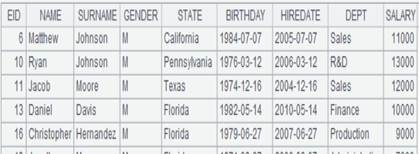
=demo.query("select EID,NAME,SALARY from EMPLOYEE").(~. array().concat@c()) |
Return a sequence of strings:
|
|
12 |
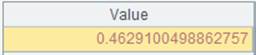
=A11.regex@p("(.*),(V.*),(.*)";id,name,salary) |
Use @p option to parse numeric strings in the result table sequence into numeric values:
|
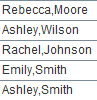

Related function:
cs .regex()
Description:
Attach the action of matching the regular expression to a cursor and return the original cursor.
Syntax:
cs.regex(rs,Fi,…)
Note:
The function attaches a computation to cursor cs, which matches the string members in cursor cs with regular expression rs, forms a table sequence consisting of Fi fields and returns it to the original cursor cs. It supports multicursors.
This is a delayed function.
Parameter:
|
cs |
A cursor whose members are strings. |
|
rs |
Regular expression. |
|
Fi |
Resulting field name. |
Option:
|
@c |
Case insensitive. |
|
@u |
Use Unicode to match. |
|
@p |
Parse numeric strings into numbers. |
Return value:
Cursor
Example:
|
|
A |
|
|
1 |
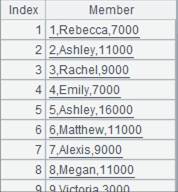
["1,Rebecca","2,ashley","3,Rachel","4,Emily","5,Ashley","6,Matthew", "7,Alexis","8,Megan","9,Victoria","10,Ryan"] |
|
|
2 |
=A1.cursor() |
Return a cursor. |
|
3 |
=A2.regex("(.*),(A.*)";id,name) |
Attach a computation to cursor A2, which will match members starting with A after the comma and return the original cursor A2; the computation is by default case sensitive. |
|
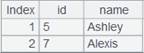
4 |
=A2.fetch() |
Fetch data from cursor A2 where A3’s computation is executed:
|
Use @c option to enable a case-insensitive computation:
|
|
A |
|
|
1 |
["1,Rebecca","2,ashley","3,Rachel","4,Emily","5,Ashley","6,Matthew", "7,Alexis","8,Megan","9,Victoria","10,Ryan"] |
|
|
2 |
=A1.cursor() |
Return a cursor. |
|
3 |
=A2.regex@c("(.*),(A.*)";id,name) |
Attach a computation to cursor A2, which will match members starting with A or a after the comma and return the original cursor A2; @c option works to enable a case-insensitive computation. |
|
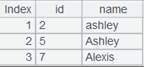
4 |
=A2.fetch() |
Fetch data from cursor A2 where A3’s computation is executed:
|
When @u option works:
|
|
A |
|
|
1 |
["销售部,李英梅","人事部,王芳","技术部,张峰","销售部,孙超"] |
|
|
2 |
=A1.cursor() |
Return a cursor. |
|
3 |
=A2.regex@u("(\\u9500\\u552e\\u90e8),(.*)";部门,员工姓名) |
Attach a computation to cursor A2, which, with @u option, will match members starting with "销售部" and return the original cursor A2. |
|
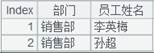
4 |
=A2.fetch() |
Fetch data from cursor A2 where A3’s computation is executed:
|
When @p option is present:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,SALARY from EMPLOYEE").(~. array().concat@c()) |
Return a cursor, whose content is as follows:
|
|
2 |
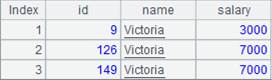
=A1.regex@p("(.*),(V.*),(.*)";id,name,salary) |
@p option works to parse numeric strings in the result table sequence into numbers. |
|
3 |
=A2.fetch() |
Fetch data from cursor A1, perform A2’s computation ,and return the following result:
|


Related function: