news()
Here’s how to use news() function.
A.news( X;xi:Fi,… )
Description:
Compute each member of a sequence according to the specified condition to generate multiple records and concatenate them into a new table sequence.
Syntax:
A.news(X;xi:Fi,…)
Note:
The function computes expression xi on each member of sequence A and sequence/integer X, generate multiple records and concatenate them to generate a new table sequence.
Parameter:
|
A |
A sequence. |
|
X |
A sequence/integer; can be understood as to(X) when it is an integer, meaning performing X number of computations on sequence A. |
|
xi |
An expression, whose results will be field values; the sign ~ used in the parameter references data from X instead of A. |
|
Fi |
Field name of the result sequence; when omitted, field names are xi by default, and use the original field names when xi is #i. |
Option:
|
@1 |
Left join, which creates an empty record when X is empty; here it is number 1 instead of letter l. |
|
@m |
Use parallel processing to increase performance. |
|
@q |
Return a sequence of sequences when there is only one parameter xi and parameter Fi is absent and when the result of computing xi is a sequence. |
Return value:
Table sequence
Example:
When A is a sequence
|
|
A |
|
|
1 |
[1,2,3,4,5] |
|
|
2 |
=A1.news([10,20]; A1.~:a,~:b,a*b) |
Parameter X is a sequence and compute members of A and X one by one, that is, use A1’s members as values of field a, members of [10,20] as values of field b and result values of a*b as values of the 3rd field; as parameter Fi is absent, use parameter xi as field names.
|
|
3 |
=A1.news(2; A1.~:a, ~:b,a*b) |
Parameter X is an integer, which is equivalent to to(2), and compute each of A1’s member two times.
|

When A is a table sequence
|
|
A |
|
|
1 |
=demo.query("select top 5 ID,NAME,BIRTHDAY,DEPT,SALARY from EMPLOYEE") |
|
|
2 |
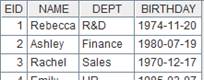
=A1.news(~;NAME,age(BIRTHDAY):AGE) |
Parameter X is a table sequence and symbol ~ is understood as member of A1; compute A1 and return records consisting of NAME field and AGE field, where AGE field is computed from A1’s BIRTHDAY field.
|
|
3 |
=A1.news(3;EID,NAME,SALARY*~:Salary) |
Parameter X is integer 3 and compute each member of A1 three times; ~ is understood as the current number of computations.
|
When A is a record sequence
|
|
A |
|
|
1 |
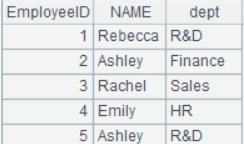
=demo.query("select top 10 EID,NAME,DEPT,GENDER,SALARY from EMPLOYEE") |
|
|
2 |
=A1.group(DEPT).(~.group(GENDER)) |
Group table sequence A1 by DEPT and then group the result by GENDER.
|
|
3 |
=A2.news(~;A2.~.DEPT,A2.~.~.GENDER,A2.~.~.avg(SALARY):AvgSalary) |
Get DEPT and GENDER values from A2’s group and calculate average salary of each GENDER in each DEPT.
|
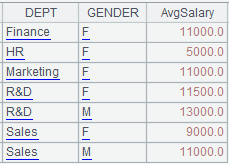
When parameter xi uses #i
|
|
A |
|
|
1 |
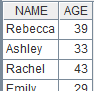
=demo.query("select top 10 EID,NAME,BIRTHDAY,GENDER,SALARY from EMPLOYEE") |
|
|
2 |
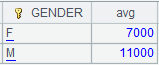
=A1.group(GENDER;~:GenderGroup,~.avg(SALARY):Avg) |
Group A1 by GENDER and calculate average salary in each group.
|
|
3 |
=A2.news(GenderGroup;EID,#2,GENDER, age(~.BIRTHDAY):age,SALARY+1000:Nsalary,A2.Avg:AvgSalary) |
Compute the expression on each group of A2 and generate records to form a new table sequence, during which #2 represents NAME, the 2nd field of GenderGroup.
|
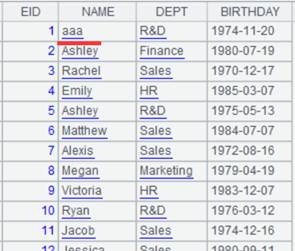
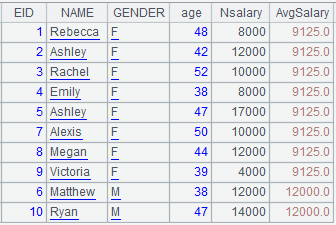
Use @1 option to perform left join
|
|
A |
|
|
1 |
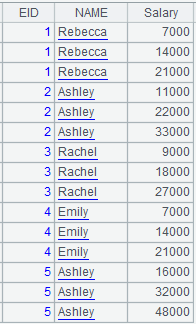
=demo.query("select top 5 EID,NAME,BIRTHDAY,GENDER,SALARY from EMPLOYEE") |
|
|
2 |
=A1.group(GENDER;~:GenderGroup) |
Group A1’s records by GENDER.
|
|
3 |
=demo.query("select top 10 EID,NAME,BIRTHDAY,GENDER,SALARY from EMPLOYEE") |
|
|
4 |
=A3.group(GENDER;avg(SALARY):avg) |
Group A3 by GENDER and calculate average salary in each group.
|
|
5 |
=A4.join(GENDER,A2:GENDER,GenderGroup) |
Perform association between A2 and A4 according to GENDER field; since A2 does not have records where GENDER is M, the corresponding GenderGroup field values are represented by nulls after table association.
|
|
6 |
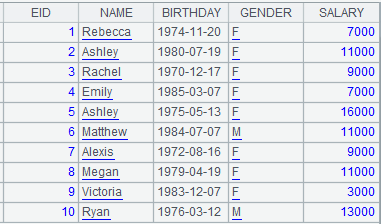
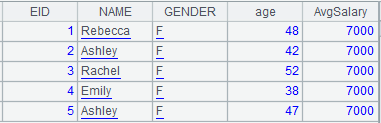
=A5.news(GenderGroup;EID,NAME,GENDER,age(~.BIRTHDAY):age,avg:AvgSalary) |
Compute the expression on record sequence A5 to generate new records, from which those whose GenderGroup is empty are by default discarded.
|
|
7 |
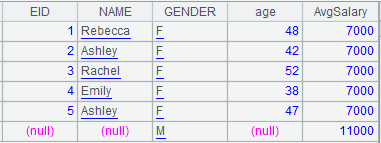
=A5.news@1(GenderGroup;EID,NAME,GENDER,age(~.BIRTHDAY):age,avg:AvgSalary) |
Use @1 option to create an empty record when record sequence X is empty
|
Use @q option to return a sequence of sequences:
|
|
A |
|
|
1 |
=file("emp.txt").cursor@w().fetch() |
Return data as follows:
|
|
2 |
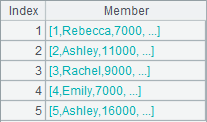
=A1.news@q(2;[A1.~(2),A1.~(3)*~]) |
With @q option, return a sequence of sequences as there is only one parameter xi and parameter Fi is absent and since the result of computing xi is a sequence:
|
Related function:
ch.news()
Description:
Generate records according to the given condition, concatenate them into a new table sequence and return it to the original channel.
Syntax:
ch.news(X;xi:Fi,…)
Note:
The function attaches a computation to channel ch, which will compute expression xi on record sequence X, use the results as values of the new field Fi to generate multiple records and form a new table sequence, and returns the result to the original channel.
This is an attachment computation.
Parameter:
|
ch |
A channel. |
|
X |
A record sequence. |
|
xi |
Expression, whose results will be field values; the sign ~ used in the parameter references data from X instead of A. The sign # is used to represent a field with a sequence number. |
|
Fi |
Field name in the given channel; will be automatically identified if the parameter is omitted. |
Option:
|
@1 |
Enable a left join; when a record in the given record sequence is empty, create an empty record for the new table sequence. |
Return value:
Channel
Example:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER,BIRTHDAY,SALARY from EMPLOYEE") |
Return a cursor. |
|
2 |
=demo.query("select EID,NAME,DEPT,GENDER,BIRTHDAY,SALARY from EMPLOYEE") |
Return a table sequence:
|
|
3 |
=A2.group(GENDER;~:gup) |
Group table sequence A2 by GENDER field and return the following result:
|
|
4 |
=A1.groupx(GENDER;avg(SALARY):avg) |
Group table sequence A1 by GENDER field, compute average SALARY values in each group and return a cursor. Below is the returned data:
|
|
5 |
=A4.join(GENDER,A3:GENDER,gup) |
Attach a computation to cursor A4, which will perform a foreign-key-style join with table A3, and return the original cursor A4. Below is the returned data of A4 executing A5’s compuation:
|
|
6 |
=channel(A5) |
Create a channel and be ready to push cursor A5’s data to the channel, but the push action needs to wait. |
|
7 |
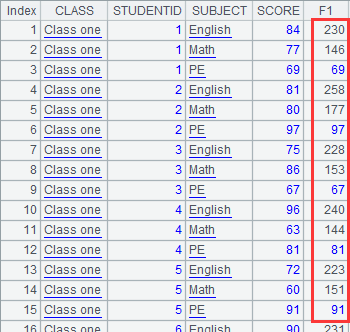
=A6.news(gup;EID,#2:Lname,GENDER,age(~.BIRTHDAY):Age,SALARY+50: Salary,avg:AvgSalary) |
Attach a computation to channel A6, which will get values for gup table - #2:Lname means renaming the table’s second field Lname, and form a table sequence consisiting of fields EID, Lname,GENDER, Age, Salary and AvgSalary, and return the result to the original channel. |
|
8 |
=A6.fetch() |
Execute the result set function in channel A6 and keep the current data in channel. |
|
9 |
=A5.fetch() |
Fetch data from cursor A5 while pushing data to channel A6 to execute the attached computation and keep the result. |
|
10 |
=A6.result() |
Get channel A6’s result:
|


Use @1 option:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER,BIRTHDAY,SALARY from EMPLOYEE") |
Return a cursor. |
|
2 |
=demo.query("select EID,NAME,DEPT,GENDER,BIRTHDAY,SALARY from EMPLOYEE where GENDER='M' ") |
Return a table sequence:
|
|
3 |
=A2.group(GENDER;~:gup) |
Group table sequence A2 by GENDER field and return the following result:
|
|
4 |
=A1.groupx(GENDER;avg(SALARY):avg) |
Group table sequence A1 by GENDER field, compute average SALARY values in each group and return a cursor. Below is the returned data:
|
|
5 |
=A4.join(GENDER,A3:GENDER,gup) |
Attach a computation to cursor A4, which will perform a foreign-key-style join with table A3, and return the original cursor A4. Below is the returned data of A4 executing A5’s compuation:
|
|
6 |
=channel(A5) |
Create a channel and be ready to push cursor A5’s data to the channel, but the push action needs to wait. |
|
7 |
=A6.news@1(gup;EID,NAME,GENDER,age(~.BIRTHDAY):Age,Salary,avg:AvgSalary) |
Attach a computation to channel A6, which will get values for gup table - #2:Lname means renaming the table’s second field Lname, and form a table sequence consisiting of fields EID, Lname,GENDER, Age, Salary and AvgSalary, and return the result to the original channel. Use @1 option to perform a left join; create an empty record for the result table sequence when a record in the record sequene is empty. |
|
8 |
=A6.fetch() |
Execute the result set function in channel A6 and keep the current data in channel. |
|
9 |
=A5.fetch() |
Fetch data from cursor A5 while pushing data to channel A6 to execute the attached computation and keep the result. |
|
10 |
=A6.result() |
Get channel A6’s result:
|


cs.news()
Description:
Generate multiple records based on a record sequence, concatenate them into a new table sequence and return it to the original cursor.
Syntax:
cs.news(X;xi:Fi,…)
Note:
The function attaches a computation to cursor cs, which computes expression xi on record sequence X , makes the results values of the new field Fi, and generates multiple records to form a new table sequence, and returns the table sequence to the original cursor cs.
This is a delayed function.
Parameter:
|
cs |
A cursor. |
|
X |
Record sequence. |
|
xi |
An expression, whose values are uses as the new field values. It is treated as null if omitted; in that case, : Fi can’t be omitted. The sign # is used to represent a field with a sequence number. |
|
Fi |
Filed name of the new cs; use the identifiers parsed from expression xi if it is omitted. |
Option:
|
@1 |
Left join, which creates an empty record when record sequence X is empty. |
Return value:
Cursor
Example:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER,BIRTHDAY,SALARY from EMPLOYEE") |
Return a cursor.
|
|
2 |
=demo.query("select EID,NAME,DEPT,GENDER,BIRTHDAY,SALARY from EMPLOYEE") |
Return a table sequence:
|
|
3 |
=A2.group(GENDER;~:gup) |
Group table sequence A2 by GENDER field and return result set as follows:
|
|
4 |
=A1.groupx(GENDER;avg(SALARY):avg) |
Group cursor A1 by GENDER field, compute average SALARY value in each group and return a cursor; below is data in the result cursor:
|
|
5 |
=A4.join(GENDER,A3:GENDER,gup) |
Attach a computation to cursor A4, which performs foreign key join with A3 and return the original cursor A4; below is the data of cursor A4 where A5’s computation is executed:
|
|
6 |
=A4.news(gup;EID,#2:Lname,GENDER,age(~.BIRTHDAY):Age,SALARY+50: Salary,avg:AvgSalary) |
Attach a computation to cursor A4 to compute gup field values, renames the 2nd field Lname using expression #2:Lname, form a table sequence consisting of EID, Lname, GENDER, Age, Salary and AvgSalary to return cursor A4, and returns the original cursor. |
|
7 |
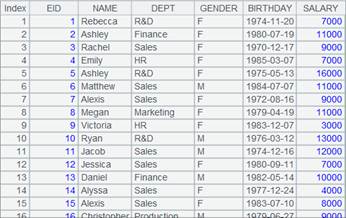
=A4.fetch() |
Fetch data from cursor A4 where A6’s computation is executed (it would be better to fetch data in batches when a huge amount of data is involved):
|


When @1 option works:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER,BIRTHDAY,SALARY from EMPLOYEE") |
Return a cursor.
|
|
2 |
=demo.query("select EID,NAME,DEPT,GENDER,BIRTHDAY,SALARY from EMPLOYEE where GENDER='M' ") |
Return a table sequence:
|
|
3 |
=A2.group(GENDER;~:gup) |
Group table sequence A2 by GENDER field and return result set as follows:
|
|
4 |
=A1.groupx(GENDER;avg(SALARY):avg) |
Group cursor A1 by GENDER field, compute average SALARY value in each group and return a cursor; below is data in the result curso
|
|
5 |
=A4.join(GENDER,A3:GENDER,gup) |
Attach a computation to cursor A4, which performs foreign key join with A3 and returns the original cursor A4; below is data in cursor A4 where the attached computation is executed:
|
|
6 |
=A4.news@1(gup;EID,NAME,GENDER,age(~.BIRTHDAY):Age,Salary,avg:AvgSalary) |
Attach a computation to cursor A4 to compute gup field values, form a table sequence consisting of EID, NAME, GENDER, Age, Salary and AvgSalary to return cursor A4, and returns the original cursor. @1 option enables left join to create an empty record when the corresponding record in record sequence X is empty. |
|
7 |
=A4.fetch() |
Fetch data from cursor A4 where A6’s computation is executed; below is the result set:
|


Related functions:
A.news(X;xi:Fi,…)
T.news( A/cs,K,x:C,…;wi,... )
Description:
Return a table sequence/cursor consisting of the specified fields according to the correspondence between the table sequence/cursor’s key and the corresponding field in the composite table.
Syntax:
T.news(A/cs:K,x:C,…;wi,...)
Note:
Composite table T is the subtable and table sequence/cursor A/cs is the primary table. They have a many-to-one relationship. The function matches A/cs’s key (/dimension) field with the corresponding fields of T (begin the correspondence from the first field) and returns a table sequence/cursor made up of x:C fields. It is required that A/cs be ordered by the key (/dimension) and the key (/dimension) has the same order as T’s first field.
With a table sequence parameter, the function returns a table sequence, and with a cursor parameter, it returns a cursor or a multicursor.
Align the returned result set to T and set key/dimension for it; copy records of the primary table.
Parameter:
|
T |
A composite table. |
|
A/cs |
A table sequence/cursor/composite table cursor. |
|
K |
A/cs’s field name; when it is specified, use it to match with T’s first field; when it is absent, use A/cs’s key (/dimension) to perform the matching; when there are multiple Ks, use colon (:) to separate them. |
|
x |
Field names or aggregate function count/sum/max/min/avg. |
|
C |
Column alias. |
|
wi |
Filtering condition on T; retrieve the whole set when this parameter is absent; separate multiple conditions by comma(s) and their relationships are AND. Besides regular filtering expressions, you can also use the following five types of syntax in a filtering condition, where K is a non-key field in entity table T: 1.K=w w usually uses expression Ti.find(K) or Ti.pfind(K), where Ti is a table sequence. When value of w is null or false, the corresponding record in the entity table will be filtered away; when w is expression Ti.find(K) and the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K; when w is expression Ti.pfind(K) and the to-be-selected fields C,... contain K, sequence numbers of K values in Ti will be assigned to K. 2.(K1=w1,…Ki=wi,w) Ki=wi is an assignment expression. Generally, parameter wi can use expression Ti.find(Ki) or Ti.pfind(K), where Ti is a table sequence; when wi is expression Ti.find(Ki) and the to-be-selected fields C,... contain Ki, Ti’s referencing field will be assigned to Ki correspondingly; when wi is expression Ti.pfind(Ki) and the to-be-selected fields C,... contain Ki, sequence numbers of Ki values in Ti will be assigned to Ki. w is a filter expression; you can reference Ki in w. 3.K:Ti Ti is a table sequence. Compare Ki value in the entity table with key values of Ti and discard records whose Ki value does not match; when the to-be-selected fields C,... contain K, Ti’s referencing field will be assigned to K. 4.K:Ti:null Filter away all records that satisfy K: Ti. |
Option:
|
@r |
A composite table. |
Return value:
Table sequence/Cursor
Example:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT STUDENTID,CLASS,SUBJECT,SCORE FROM SCORES") |
Return a cursor. |
|
2 |
=file("scores-news.ctx") |
|
|
3 |
=A2.create@y(#STUDENTID,#CLASS,SUBJECT,SCORE) |
Create a composite table and set STUDENTID and CLASS as its dimension. |
|
4 |
=A3.append@i(A1) |
|
|
5 |
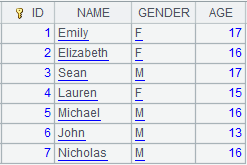
=connect("demo").query("SELECT ID,NAME,GENDER,AGE FROM STUDENTS") |
Return a table sequence.
|
|
6 |
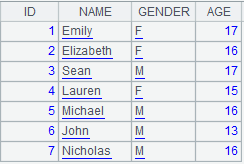
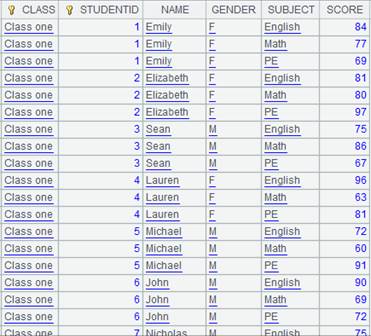
=A4.news(A5:ID,CLASS,STUDENTID,NAME,GENDER,SUBJECT,SCORE) |
A4 is the subtable and A5 is
the primary table; perform the matching according to table sequence A5’s ID
field and T’s first key field STUDENTID and return a table sequence
consisting of CLASS, STUDENTID, NAME, GENDER, SUBJECT and SCORE fields; copy
records of the primary table and return
the following result: |
|
7 |
=A5.keys(ID) |
Set ID as table sequence A5’s key.
|
|
8 |
=A4.news(A7,CLASS,STUDENTID,NAME,GENDER,SUBJECT,SCORE) |
As parameter K is absent, perform the matching according to A7’s key and the composite table’s first key field and return same result as A6. |
|
9 |
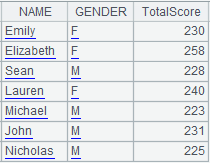
=A4.news@r(A7,NAME,GENDER,sum(SCORE):TotalScore) |
Use @r option to summarize data in the subtable.
|
|
10 |
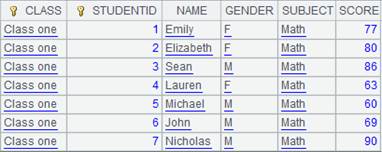
=A4.news(A7,CLASS,STUDENTID,NAME,GENDER,SUBJECT,SCORE;CLASS=="Class one",SUBJECT=="Math") |
Perform filtering on A4’s data according to filter condition: CLASS=="Class one" and SUBJECT=="Math" during association.
|

When there are multiple K parameters:
|
|
A |
|
|
1 |
=file("sco.ctx").open() |
Open a composite table as follows:
|
|
2 |
=file("stu.txt").import@t() |
Return a table sequence:
|
|
3 |
=A1.news(A2:Class:StudentID,NAME,SUBJECT,SCORE) |
A1 is the subtable and A2 is the primary table; perform the matching between table sequence A2’s Class and StudentID fields and T’s first two fields – Class and StudentID – and return a table sequence consisting of NAME,SUBJECT,SCORE; copy records of the primary table and return the following result:
|
|
4 |
=A1.news@r(A2:Class:StudentID,NAME,sum(SCORE):TotalScore) |
Use @r option to summarize data in the subtable.
|
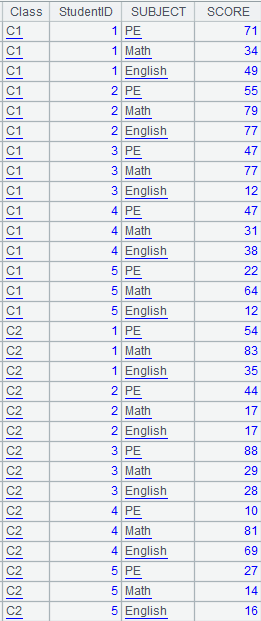

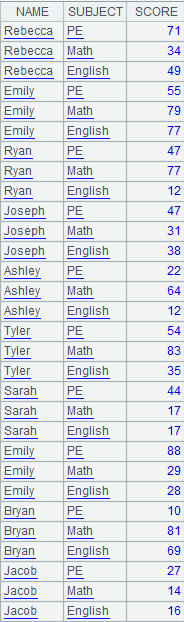
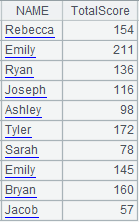
Use special types of filtering conditions:

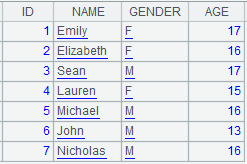
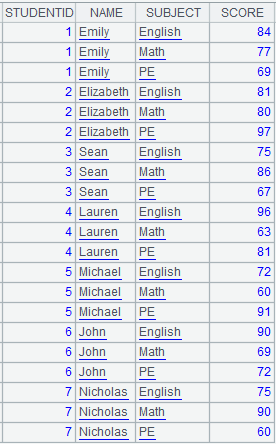
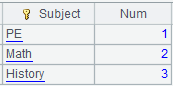
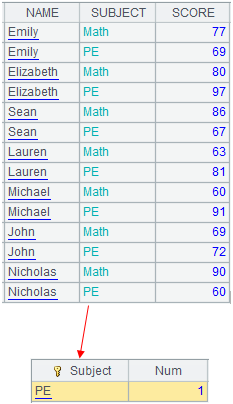
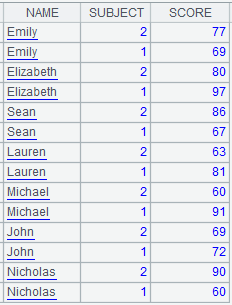
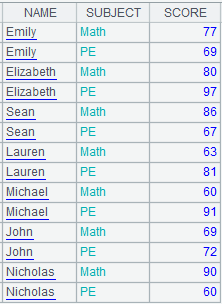
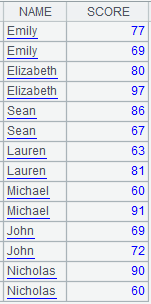
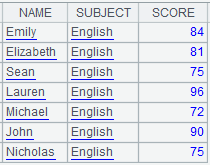

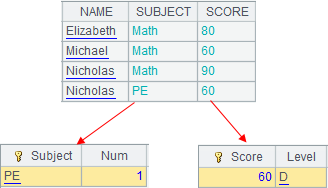
Note:
The difference between T.new() and T.news() is that the former works when T and A/cs has a one-to-many relationship and the latter operates when T and A/cs has a many-to-one relationship.