cs.fetch()
Description:
Open a cursor/cluster cursor/multicursor and fetch records from it.
Syntax:
cs.fetch(n;x)
Note:
The function opens cursor/cluster cursor/multicursor cs and retrieves records from it.
When parameter n is present, the function reads n records; when parameter x is present, fetch records continuously until the value of expression x is changed (in this case x isn’t a logical value) or expression x becomes true (in this case x is a logical value);
Only one of the parameters n and x is valid. When both n and x are omitted, the function fetches all existing records in cs and then closes the cursor.
The function returns the fetching result as a sequence/record sequence/table sequence or returns null if the cursor moves to the end. The order of result records fetched from a multicursor is unfixed.
The function is often used to retrieve a large amount of data in batches.
Parameter:
|
cs |
A cursor/cluster cursor/multicursor |
|
n |
A positive integer |
|
x |
Grouping expression, according to which cs is sorted. With x, n will be ignored |
Option:
|
@0 |
Won’t actually fetched out the returned data from the cursor. The option enables an action functionally equivalent to copying the data; it doesn’t support parameter x |
|
@x |
Close the cursor after data is fetched |
Return value:
A sequence/record sequence/table sequence
Example:
cs is a cursor and when parameter n is present:
|
|
A |
|
|
1 |
=connect("demo").cursor("select top 10 EID,NAME,DEPT,SALARY from employee") |
There are 10 records in the returned cursor. |
|
2 |
=A1.fetch(3) |
As parameter n is 3, the function fetches 3 records from cursor A1 (Fetch data in batches when there is a huge amount of data in the cursor in real-world businesses):
|
|
3 |
=A1.fetch(5) |
Continue to fetch data from cursor A1; as A2 already fetches 3 records, here the fetch function fetches 5 records beginning from the 4th one:
|
|
3 |
>A1.close() |
Close the cursor. |


cs is a cursor, and when parameter x is present and x isn’t a logical value:
|
|
A |
|
|
1 |
=connect("demo").cursor("select top 20 EID,NAME,DEPT,SALARY from employee").sortx(DEPT) |
Data in the returned cursor is ordered by DEPT field. |
|
2 |
=A1.fetch(;DEPT) |
Parameter x is DEPT and the fetch function fetches records until DEPT value is changed; below is the returned result:
|
|
3 |
=A1.fetch() |
As no parameters are present, the fetch function fetches all existing records in the cursor and closes the cursor:
|
|
4 |
=A1.fetch() |
As A3 already fetches all records out of the cursor and closes the cursor, A4 returns null. |


cs is a cursor, and when parameter x is present and x is a logical value:
|
|
A |
|
|
1 |
=connect("demo").cursor("select top 15 EID,NAME,DEPT,SALARY from employee").sortx(-SALARY) |
Data in the returned cursor is ordered by SALARY field in descending order. |
|
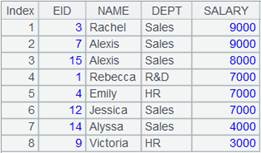
2 |
=A1.fetch(2;SALARY<10000) |
As parameter x is present, ignore parameter n and the fetch function fetches records from the cursor until the result of SALARY<10000 is true; below is the returned result:
|
|
3 |
=A1.fetch() |
Fetch the rest of records in the cursor and close the cursor:
|

When cs is a cluster cursor:
|
|
A |
|
|
1 |
[192.168.0.110:8281,192.168.18.143:8281] |
A sequence of nodes. |
|
2 |
=file("emp.ctx":[1,2], A1) |
1.emp.ctx on node 192.168.0.110 contains records where GENDER field values are F; 2.emp.ctx on node 192.168.18.143 contains records GENDER where GENDER field values are M. |
|
3 |
=A2.open() |
Open A2’s cluster homo-name file group. |
|
4 |
=A3.cursor() |
Return a cluster cursor. |
|
5 |
=A4.fetch() |
Open A4’s cluster cursor, fetch all records, and close the cursor. |
With @0 option, the returned data won’t be fetched from the cursor:
|
|
A |
|
|
1 |
=connect("demo").cursor("select top 10 EID,NAME,DEPT,SALARY from employee") |
Return a cursor where there are 10 records. |
|
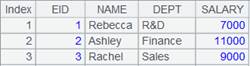
2 |
=A1.fetch@0(3) |
With @0 option, fetch function reads 3 records in cursor A1 but does not fetch the out:
|
|
3 |
=A1.fetch() |
Read the rest of records from cursor A1 and all records are fetched out now; fetch function returns 10 records:
|

With @x option, close the cursor after data is fetched out:
|
|
A |
|
|
1 |
=connect("demo").cursor("select top 10 EID,NAME,DEPT,SALARY from employee") |
Return a cursor where there are 10 records. |
|
2 |
=A1.skip(5) |
Skip 5 records in cursor A1. |
|
3 |
=A1.fetch@x(3) |
Fetch 3 recrods form cusor A1; as A2 skips 5 records, here fetch function fetches 3 records beginning from the 6th one:
With @x option, fetch function closes the cursor after it finishes fetching data out. |
|
4 |
=A1.fetch() |
As A3 closes the cursor, fetch function returns null. |

When cs is a multicursor:
|
|
A |
|
|
1 |
=file("D:/txt_files/orders.txt").cursor@m() |
Return a multicursor. |
|
2 |
=A1.fetch() |
Fetch records from the multicursor. |
|
3 |
=file("D://tb1.txt").import() |
tb1.txt contains 10w rows of data. |
|
4 |
=A3.cursor() |
Generate a unicursor. |
|
5 |
=A4.fetch(15000) |
Fetch the first 15,000 rows:
|
|
6 |
=A3.cursor@m(10) |
Generate a multicursor. |
|
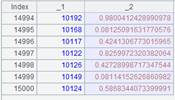
7 |
=A6.fetch(15000) |
Fetch the first 15,000 rows:
Compared with the fetching result in A5, the detailed data is different. This is because the result of fetching data from a multicursor is the merge of records fetched from different subcursors while fetching data from a unicursor is in order. |
Related function: