A.i d()
Description:
Get distinct values from a sequence.
Syntax:
A.id(xi,…;n)
Note:
The function gets top n distinct values of the expressions xi,…. If the number of distinct values in an expression x is less than n, return all distinct values as a sequence; the result set consists of one ordinary sequence when there is only one expression x.
Parameter:
|
xi |
An expression; use ~ to represent x if the latter is omitted |
|
n |
The number of to-be-retrieved distinct values counting from the beginning; return all values if it is absent |
Option:
|
@o |
Without sorting, remove the neighboring duplicate members only |
|
@u |
Do not sort the result set by x; it doesn’t work with @o |
|
@h |
Used over a grouped table with each group ordered to speed up grouping |
|
@0 |
Discard members on which expression x is computed and gets empty result |
|
@m |
Enable parallel processing to increase performance of complex computations on a large volume of data, with indefinite computing order; the parameter and @o option are mutually-exclusive |
|
@n |
Judge whether a member is distinct or not according to position when there is only one xi and xi is a natural number |
|
@b |
Judge whether a member is distinct or not according to the bit length in a byte in order to reduce storage usage when there is only one xi and xi is a natural number |
Return value:
Sequence
Example:
|
|
A |
|
|
1 |
=demo.query("select * from EMPLOYEE") |
|
|
2 |
=A1.id(DEPT) |
Sort members in ascending order. |
|
3 |
=A1.id@o(DEPT) |
No sorting. |
|
4 |
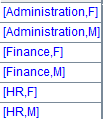
=A1.id([DEPT,GENDER]) |
Get the distinct values after sorting by DEPT & GENDER. |
|
5 |
=["a","b","c","a"].id() |
Omitting x indicates it is the sequence members themselves that will be computed to get the distinct values. Return ["a","b","c"] as with this case. |
|
6 |
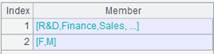
=A1.id@u([DEPT,GENDER]) |
Do not sort the result set by x. |
|
7 |
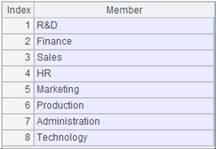
=A1.id(DEPT,GENDER) |
Return all distinct values as parameter n is absent.
|
|
8 |
=A1.id(DEPT,GENDER;4) |
Return the first 4 distinct values; return all GENDER values as the field has less than 4 distinct values.
|
|
9 |
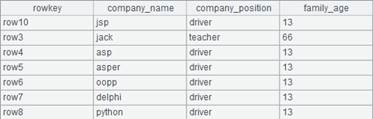
=file("D:/emp10.txt").import@t() |
For
data file emp10.txt, every 10
records are ordered by DEPT. |
|
10 |
=A9.id@h(DEPT) |
As A19 is grouped and ordered by DEPT, @h option is used to speed up grouping.
|







|
|
A |
|
|
1 |
=demo.query("select * from DEPT") |
|
|
2 |
=A1.id(FATHER) |
Return value: [null,1,2,11,12]. |
|
3 |
=A1.id@0(FATHER) |
Return value: [1,2,11,12] . |

Related function: