Sequence and Table Sequence
Sequence, table sequence (TSeq) and record sequence (RSeq) are the most common data types esProc uses. This section will explain their respective characteristics as well as relations between them.
2.3.1 Sequences-ordered generic sets
Collectivity
A sequence consists of multiple data items, which are called members of the sequence. A member can be any data type, such as string, integer, float and date, and is allowed to be null. A sequence has the general characteristics of a set, and can be manipulated by set operations. For example:
|
|
A |
|
1 |
[] |
|
2 |
[5,6,7] |
|
3 |
[red,blue,yellow] |
|
4 |
=["blue","yellow","white"] |
|
5 |
=A3^A4 |
In the above cellset, the values of A1, A2 and A3 are as follows:

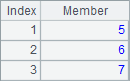
The values of A1, A2 and A3 are all sequences. A1’s is an empty sequence. The members of A2’s sequence are integers, thus it is also called an integer sequence. A3’s sequence has string members.
In A4, an expression is used to generate a sequence. Different from the constant sequence in A3, the strings in the expression should be placed in double quotes. A5 computes the intersection of the sequence in A3 and the one in A4, with a result being a sequence too. The results of A4 and A5 are as follows:

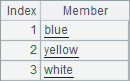
Genericity
A sequence is a generic set, which is allowed to have members of various data types. A member can also be a sequence. For example:
|
|
A |
B |
|
1 |
[] |
=[1,date("2014-05-01")] |
|
2 |
[5,6,7] |
=["blue",[],[5,6,7]] |
|
3 |
[red,blue,yellow] |
=["blue",A1,A2] |
In the cellset, members of the sequence in B1 are an integer and a date; members of B2’s sequence, which equals the expression in B3, include sequences. The results of B1, B2 and B3 are as follows:

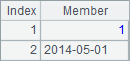
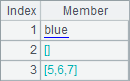
You can click the sequence members, which are displayed in cyan, and see the details.
Orderliness
Generally, a set is unordered, that is, two sets with same members arranged in different ways are equal. But a sequence is ordered, which means two sequences with same members arranged in different ways are not equal. For example:
|
|
A |
B |
|
1 |
[Mike,Tom] |
[Tom,Mike] |
|
2 |
=A1==B1 |
|
A2 uses the expression =A1==B1 to check if the two sequences are equal. The result is false:
![]()
Orderliness is a universal feature of business data. For example, that Mike comes before Tom may mean that Mike performs better in school; and sorting sales amounts by month can clearly show their changing pattern. It is more convenient to use a sequence to perform order-related calculations. For example:
|
|
A |
|
1 |
[Mike,Tom] |
|
2 |
=A1(2) |
|
3 |
=A1.m(-1) |
|
4 |
=A1.pos("Tom") |
|
5 |
=A1.rvs() |
A2 fetches the second member of the sequence. The operation can also be expressed as =A1.m(2). A3 fetches the last member of the sequence. A4 gets the ordinal number of member Tom. A5 reverses the sequence to generate a new one. The results of A2, A3, A4 and A5 are as follows:
![]()
![]()
![]()

Other order-related operations include insert operation, delete operation, modify operation, copy operation, compare operation, aggregate operations, getting a sub-sequence, sort operation, rank operation, set operations, mutual transformation of strings and sequences, etc.
An integer sequence is a sequence whose members are integers. There are a set of methods to access an integer sequence. For example:
|
|
A |
|
1 |
=to(2,5) |
A1 generates a sequence as follows:
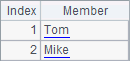
To generate a sequence beginning with 1, such as =to(1,5), it can be abbreviated to =to(5).
2.3.2 TSeqs-sequences with structure
esProc inherits the concept of data table in relational databases, and defines it as table sequence. Consistent with the relational database’s definition of the data table, every table sequence has its own data structure, which consists of fields. Members of a table sequence are called as records.
Two-dimensional structured data objects
A member of a sequence can be any data type, such as an ordinary type, a sequence and a record; while members of a table sequence must be records of the same structure. The following data object is a table sequence:
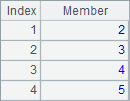
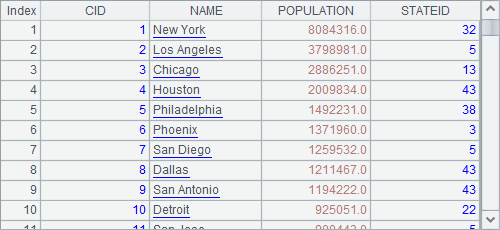
Because a table sequence is a two-dimensional structured data object, it is usually generated from SQL statements, text files, bin files, Excel files or an empty table sequence. The results of A1, A2 and A3 in the following cellset are table sequences:
|
|
A |
|
1 |
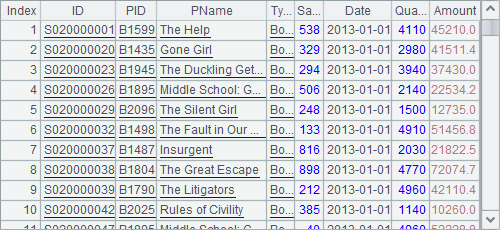
=file("Order_Books.txt").import@t() |
|
2 |
=demo.query("select * from CITIES") |
|
3 |
=create(OrderID,Client,SellerId,Amount,OrderDate) |
A1 generates a table sequence, which is the one in the above, from a text file. A2 generates a table sequence using SQL, and C1 creates an empty table sequence by specifying the field names. The table sequences in A2 and A3 are as follows:
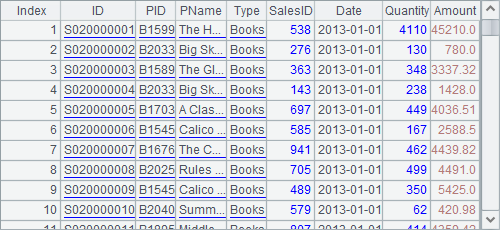
A great number of algorithms for structured data, such as data querying, data sorting, summing up values, finding average value, and merging duplicate records, can be performed on table sequences. For example:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
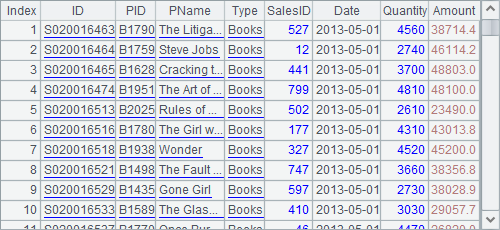
=A1.select(Amount>=20000 && month(Date)==5) |
|
3 |
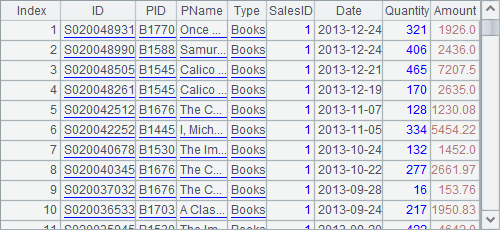
=A1.sort(SalesID,-Date) |
|
4 |
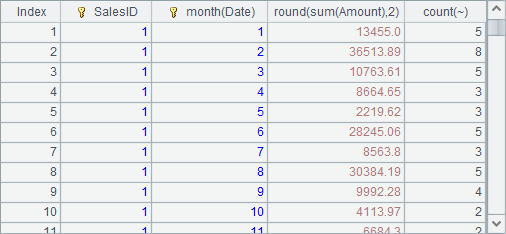
=A1.groups(SalesID, month(Date); round(sum(Amount),2), count(~)) |
A2 selects records whose Amount is greater than or equal to 20,000 and whose Date falls in the month of May:
A3 sorts the records by SalesID in ascending order and those with the same SalesID by Date in descending order:
A4 groups the records by SalesID and the month, and then sums up Amount and counts the orders in each group:
A table sequence is still a sequence, so it has the sequence’s features of collectivity and orderliness, and can use sequence-related functions. A table sequence isn’t generic in the sense of a sequence because its members must be records of the same structure. But, the field values of the records can be generic data, which in this sense is another form of genericity. Thanks to these characteristics, a table sequence is conveniently usable in handling complicated computations, compared with the traditional programming languages.
For example, to compute the monthly growth rate of the sales amount, esProc takes advantage of the table sequence’s orderliness to write the following algorithm:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
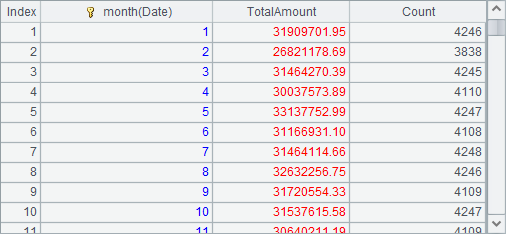
=A1.groups(month(Date); sum(decimal(string(Amount))):TotalAmount, count(~):Count) |
|
3 |
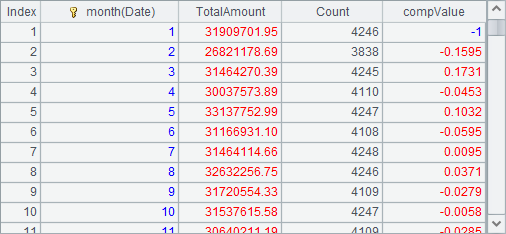
=A2.derive(round(TotalAmount/TotalAmount[-1]-1,4): compValue) |
A2 computes the total sales amount in each month:
A3 computes the final result:
This instance is based on the collectivity. Assume that in a certain business a big contract is one whose quantity is greater than 1,000 and an important contract is one whose amount is more than 10,000. Please find out: 1. Contracts that are both large and important; 2. The other contracts:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
|
|
2 |
Big |
=A1.select(Quantity>1000) |
|
3 |
Importance |
=A1.select(Amount>10000) |
|
4 |
=B2^B3 |
=A1\A4 |
B2 selects the big contracts, and then B3 selects the important ones. A4 computes the intersection of the two kinds of contracts, which is the answer to question 1:
B4 answers question 2 by computing the difference of all orders and the result of question 1:
Note: In the above code, A1 contains a table sequence, while, B2, B3, A4 and B4 are all record sequences originating from the table sequence. The difference and relation between the table sequence and the record sequence will be explained in the following section.
2.3.3 RSeq – a sequence of references of TSeq records
Obviously, if each step of computation performed on a table sequence generates a new table sequence, a great deal of memory space will be used. For instance, a table sequence, Order_Books, has 50,000 records, and 30,000 records are obtained by query. If a new table sequence is created, there would be 80,000 records in the memory. In fact, as the queried records are part of the original table sequence, it is unnecessary to create a table sequence anew. You could simply store their references in a certain type of data object. The data object that esProc uses to do this is a record sequence.
Transparency of RSeqs
Usually, it’s not necessary to differentiate between a record sequence and a table sequence, as there are also unnecessary to distinguish between references and physical data. For instance, operations like query, sort and intersection in the previous example can be performed on both record sequences and table sequences with the same syntax:
|
|
A |
B |
|
1 |
=file("Order_Books.txt").import@t() |
=A1.to() |
|
2 |
=A1.select(Amount>=20000 && month(Date)==5) |
=B1.select(Amount>=20000 && month(Date)==5) |
|
3 |
=A1.sort(SalesID,-Date) |
=B1.sort(SalesID,-Date) |
Note: A1 is a table sequence, from which the record sequence in B1 originates. The results of A2, B2, A3 and B3 are all record sequences.
Set operations can be performed between record sequences, like the manipulation of orders in TSeqs - special sequences. But there isn’t any practical significance to perform set operations between table sequences, because members of different table sequences are different objects and their intersection is always empty.
When data structure changes, esProc will automatically create a new table sequence, like what happens in one of the examples in the above where groups function is used to group and aggregate data, or where new fields are added to a table sequence using derive function.
One-way influence from TSeqs to RSeqs
Different table sequences hold different physical records, so modifying a table sequence will not affect the other ones. But, a record sequence is the references of the records of a table sequence and uses the latter’s physical data as its source; any change of the source table sequence will affect the corresponding record sequence. For example:
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
=A1.select(SalesID==363) |
|
3 |
>A1.modify(3, 1:SalesID) |
Click ![]() on the toolbar to perform the stepwise, and you
will see A1’s table sequence, where the third record’s SalesID is 363:
on the toolbar to perform the stepwise, and you
will see A1’s table sequence, where the third record’s SalesID is 363:

A2 selects from the table sequence all the records whose SalesID is 363 and creates a record sequence:
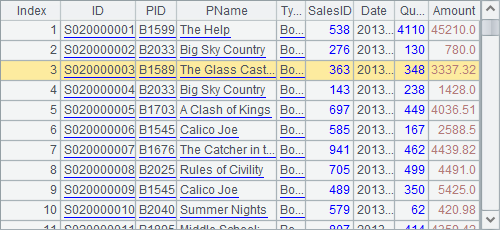
A3 modifies SalesID of the third record of A1’s table sequence by reassigning 1 to it. Then check the table sequence and you can see that the third record is modified:
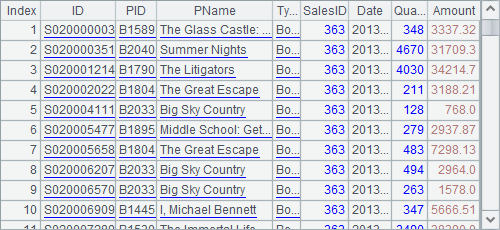
And a check of A2’s record sequence shows that the corresponding record changes too, though it isn’t modified directly. This is because it references records of the table sequence as its own records:
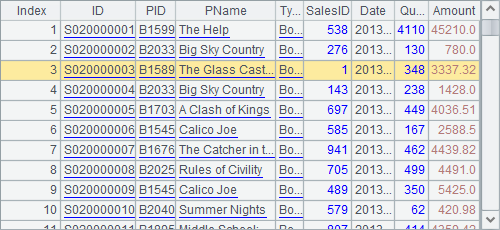
If there are multiple record sequences that use the same table sequence as their source, the correponding records in all these record sequences will change accordingly.
But in many cases, this isn’t what a programmer wants to see. Take the above case as an example. Because A3’s modification to the table sequence happens after A2 selects out the desired data (In this case, the corresponding reference hasn’t changed), in the selected data in A2 there is a record whose SalesID isn’t 363. This might cause an error in business.
In order to avoid the error, you should finish modifying the table sequence before the record sequence is created. For example:
TSeq.modify(5, 1000: Amount) / Modify the Amount field of the record whose OrderID equals 5 into 1,000, i.e., less than 2,000.
RSeq =TSeq.select(Amount>2000) / The records whose OrderID equals 5 won’t appear in the RSeq.
|
|
A |
|
1 |
=file("Order_Books.txt").import@t() |
|
2 |
>A1.modify(3, 1:SalesID) |
|
3 |
=A1.select(SalesID==363) |
First modify the original data in A2 and then select the desired data. In this way, the record sequence obtained in A3 is as follows:
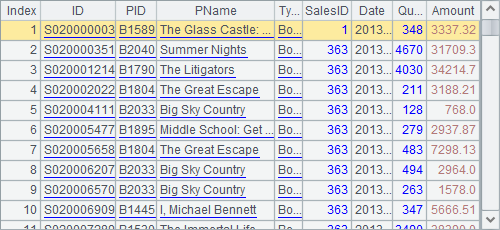
This result is what the business requires. It’s only natural for the above computing order as long as the reference relation between a table sequence and a record sequence is understood.
It’s important to note that operations to modify the original table sequence, like modify function, are not accepted in a record sequence. The relation between the two is a safe one-way influence, giving users every confidence that they’ll get the right result with the use of record sequences and table sequences.