Creating a new or different TSeq
A new table sequence can be generated by retrieving data from a database, or based on a sequence or another table sequence using new function. A different table sequence can be produced with derive function by adding one or more columns to an existing table sequence or record sequence.
3.1.1 Creating a TSeq based on existing data
A.new() function is used to create a new table sequence based on an existing sequence or table sequence. For example:
|
|
A |
|
1 |
[1,2,3,4,5] |
|
2 |
$(demo) select * from EMPLOYEE |
|
3 |
=A2.select(STATE=="Texas") |
|
4 |
=A1.new(~,~*~,~*~*~) |
|
5 |
=A2.new(EID,NAME+" "+SURNAME,GENDER,age(BIRTHDAY)) |
|
6 |
=A3.new(EID,NAME+" "+SURNAME,GENDER,STATE) |
A1 is a simple sequence. A2 is a table sequence containing employee information retrieved from the database. A3 is a record sequence made up of records of Texas employees selected from A2. A4, A5 and A6 respectively create new table sequences using new function based on a sequence, table sequence and record sequence. Here is the table sequence in A4:
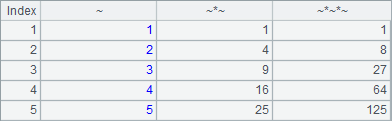
The table sequence in A5:
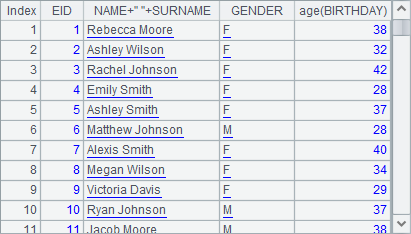
The table sequence in A6:
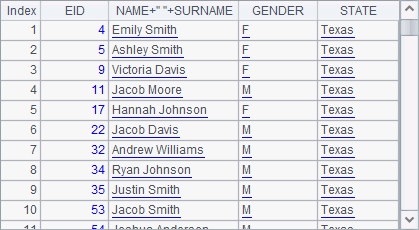
As can be seen from the above results, A.new() function loops through every member of A to compute the expressions to get a new record and and enter it into the new table sequence. The new function can reference members of A; if A is a table sequence or a record sequence, it can also reference the field values of the records for computation. By default, the field names of the new table sequence are the expressions for generating the table sequence, for instance, age(BIRTHDAY). For the fields of the new table sequence that directly migrate from the old one, they will use the old field names if they aren’t given new names, like EID and GENDER, which are also expressions for generating new fields. You can retrieve only the desired data to create a new table sequence.
Expression field names are inconvenient to use for a table sequence. New names will usually be specified for fields of the new table sequence. For example:
|
|
A |
|
1 |
[1,2,3,4,5] |
|
2 |
$(demo) select * from EMPLOYEE |
|
3 |
=A2.select(STATE=="Texas") |
|
4 |
=A1.new(~:Value,~*~:Square,~*~*~:Cube) |
|
5 |
=A2.new(EID,NAME+" "+SURNAME:FullName,GENDER, age(BIRTHDAY):Age) |
|
6 |
=A3.new(EID,NAME+" "+SURNAME:NAME,GENDER,STATE) |
Results of A4, A5 and A6 are as follows:
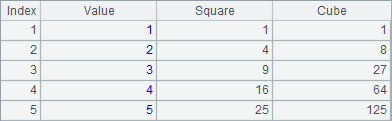
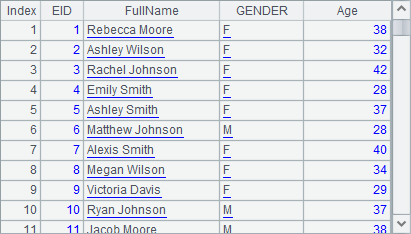
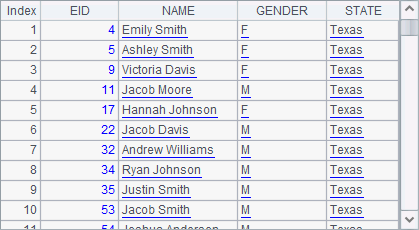
As can be seen, to rename a new field in the new function, one just need to write the desired name after the expression for generating the field, with a colon used to separate the name and the expression, like NAME+" "+SURNAME:FullName, which means that the employees’ full names are obtained according to the NAME and SURNAME fields of the records in the original table sequence and the new field is named FullName.
By the way, if it is a sequence consisting of continuous numbers according to which the new table sequence is created, such as the sequence in A1, the expression can be simply written as n.new(). For example:
|
|
A |
|
1 |
=5.new(~:Value,~*~:Square,~*~*~:Cube) |
|
2 |
$(demo) select * from EMPLOYEE |
|
3 |
=100.new(A2(~).(NAME+" "+SURNAME):Name,rand(5)+1:Group) |
A1 is the abbreviated form of the expression in A4 in the previous example, and both have the same result:
A3 also executes the new function with numbers to generate 100 records, and then put the records of the first 100 employees in the employee table into five groups randomly. The resulting table sequence is as follows:
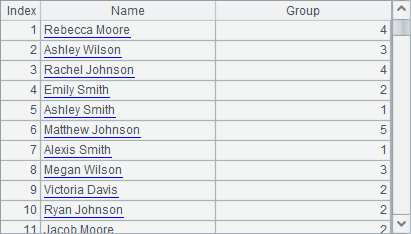
When creating a new table sequence, the new function can reference the fields of the new table sequence in its expression. For example:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE |
|
2 |
=A1.new(EID,NAME+" "+SURNAME:FullName, FullName[-1]:PREV) |
|
3 |
=A1.new(EID,NAME+" "+SURNAME:NAME) |
|
4 |
= A1.new(EID,NAME+" "+SURNAME:NAME,NAME[-1]:PREV) |
|
5 |
=A1.new(EID,NAME+" "+SURNAME:NAME, NAME[-1]+" "+ SURNAME[-1]:PREV) |
So A2 obtains the current employee’s full name and then references the full name of the previous employee in the following field when using new function to create a new table sequence. Its result is as follows:
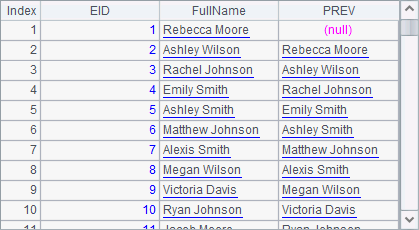
A new field name is allowed to be the same as one in the original table sequence. For instance, NAME is still used in A3 to represent the field of employees’ full names:
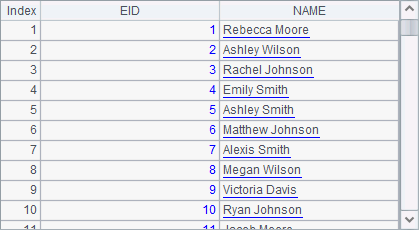
But notice that a problem thus arises in the execution of A4’s code. In A4, NAME[-1]:PREV is used to reference the name of the previous employee and name the new field PREV. Since the source table sequence in A1 also has a NAME field, which takes priority over the newly-specified one during expression parsing if the two have the same names. A4 gets the following result:
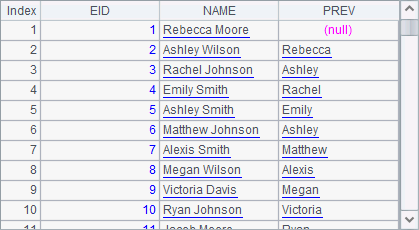
It can be seen that A4 only gets the employee names in the original table sequence, rather than the newly obtained full names.
By naming a field in the new table sequence after an old field name, one can only compute the PREV field using the fields in A1, like what A5 does. Result is as follows:
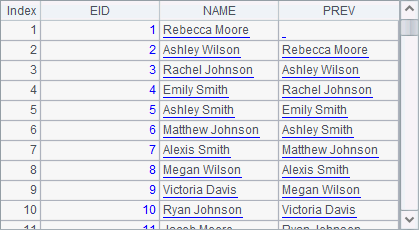
You can use @i option with the new function. If the result of computing the given field expression with a record is null, the record won’t be added to the the new table sequence. For example:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE |
|
2 |
=A1.new@i(EID,NAME+" "+SURNAME:NAME, if(GENDER=="M","Male"):Gender) |
When A2 computes the Gender field, it changes M, the value for male employees, into Male while keeping the value for femal employees as null. So the result won’t contain records of female employees. A2’s result is as follows:
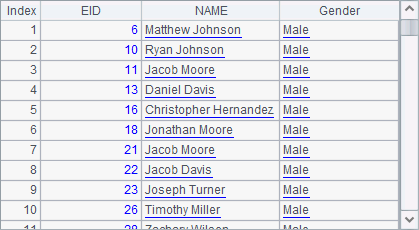
The if function can be replaced by case function in an equivalence judgement. In this case if(GENDER=="M","Male") is equivalent to case(GENDER, "M":"Male").
To generate records for a new table sequence by performing same operation on each record of a specific table sequence or on each member of a specified sequence, we can use A.news(X; xi:Fi, …) function. For example:
|
|
A |
|
1 |
[1,2,3,4,5] |
|
2 |
=A1.news(to(10, 15); A1.~:x, ~:y, x*y:x_times_y) |
|
3 |
=A1.news(["Square","Cube"]; A1.~:Value, ~:Method, if(#==1, A1.~*A1.~,A1.~*A1.~*A1.~):Result) |
|
4 |
$(demo) select * from EMPLOYEE |
|
5 |
=A4.select(DEPT=="Finance") |
|
6 |
=A5.news(rand(3); ~:BusinessTrip, A5.NAME:Name, rand(1000)*10:Cost) |
A2 calculates the product of each number in A1’s sequence and each number in a number sequence in order. Below is the result table:
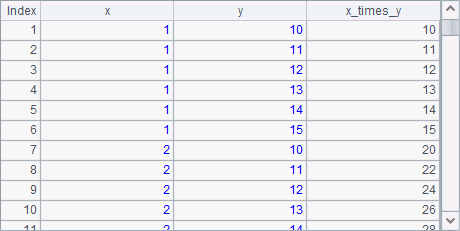
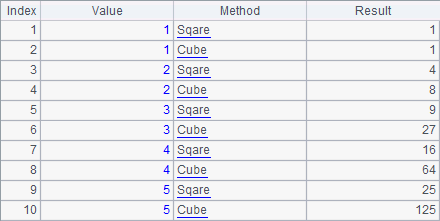
A3 calculates the square and cube of each number in A1 to generate two records for them. Below is the result table:
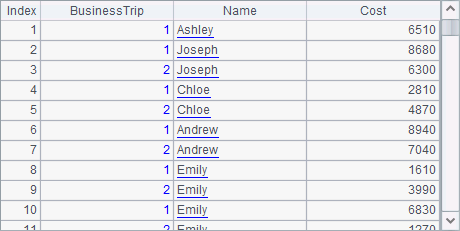
A6 generates 0~2 simulated records of business trip expenses for each employee randomly according to A5’s records of employees in Finance department. Below is the result table:
3.1.2 Creating a sequence based on existing data
The loop function A.(x) can also be used to generate data using an existing sequence, table sequence or record sequence. Here we’ll discuss its uses and compare it with A.new(). For example:
|
|
A |
|
1 |
$(demo) select * from EMPLOYEE |
|
2 |
=A1.(NAME+" "+SURNAME) |
|
3 |
=A1.( age(BIRTHDAY)) |
|
4 |
=5.([~,~*~,~*~*~]) |
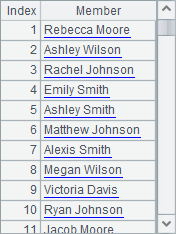
Results of A2 and A3 are as follows:
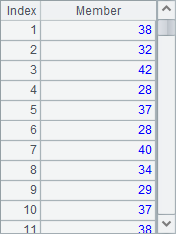
The results are sequences instead of table sequences. According to this, generally the loop function A.(x) generates a single piece of data each time.
To get multiple data at a time, use the code in a similar style as A4’s. The result will be a sequence whose members are also sequences. Below is A4’s result:
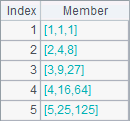
When determining an equivalence relation, we can use case function to replace if function, such as if(GENDER=="M","Male") can be written as case(GENDER, "M":"Male").
3.1.3 Deriving a TSeq by adding fields to a TSeq/RSeq
Sometimes it is no need to create a new table sequence. One just needs to add one or more computed columns as required to an existing table sequence or record sequence using the derive function to generate a different table sequence. For example:
|
|
A |
|
1 |
$(demo) select EID,NAME,SURNAME,BIRTHDAY,GENDER from EMPLOYEE |
|
2 |
=A1.derive(age(BIRTHDAY)) |
|
3 |
=A2.derive(NAME+" "+SURNAME:FullName) |
|
4 |
=A1.derive(:FullName) |
The original table sequence in A1 is as follows:
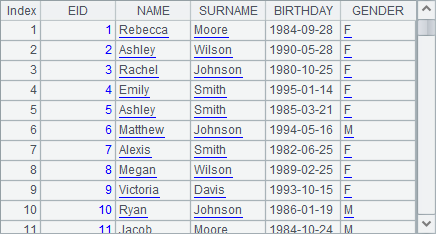
A2 derives a table sequence from A1 by adding an age field to the original table sequence with the derive function. Result is as follows:
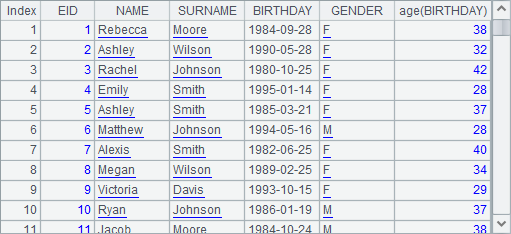
An age field derived from the BIRTHDAY field is appended to the original fields. The new field uses the expression age(BIRTHDAY) by which it is generated as its name because it hasn’t been renamed. Actually the derive function can be regarded as the simplified form of the new function. It also generates a new table sequence when executed. That’s the reason that A1’s table sequence can remain unchanged after A2 finishes creating the new table sequence.
A3 adds the FullName field to the table sequence in A2 and gets the following table sequence:
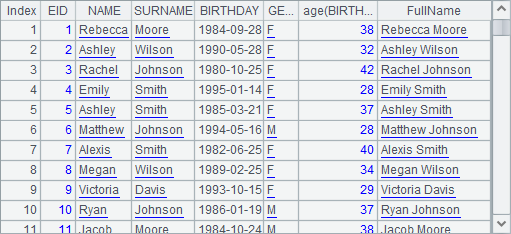
It is clear that all the fields of the table sequence in A2 have been copied, only with the new field appended. In A3’s expression, the new field is named FullName. Similarly, the operation in A3 doesn’t affect the result of A2.
A4 reuses the original table sequence in A1 and adds a new field named FullName to it, but defines no expression. Result is as follows:
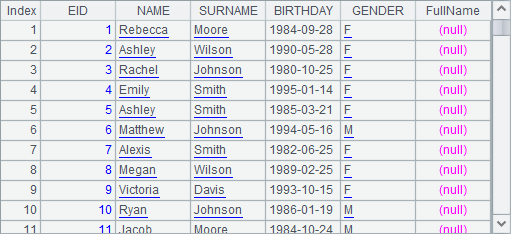
It can be seen that, without an expression, the program will generate a null field and return it.
|
|
A |
|
1 |
$(demo) select EID,NAME,SURNAME,BIRTHDAY,GENDER from EMPLOYEE |
|
2 |
=A1.derive(age(BIRTHDAY),NAME+" "+SURNAME:FullName) |
|
3 |
=A1.derive(age(BIRTHDAY):Age,string(Age)+GENDER:Group) |
You can use the derive function to add multiple fields at a time. In this example, A2’s result is as follows:
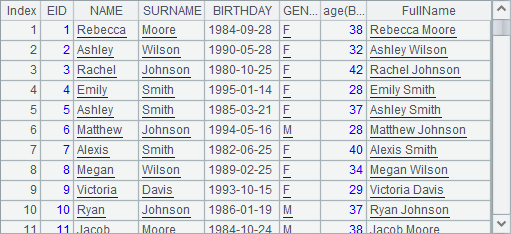
It has the same effect as adding fields step by step.
A3 adds an Age field and a Group field computed with Age field and GENDER field to the original table sequence. Result is as follows:
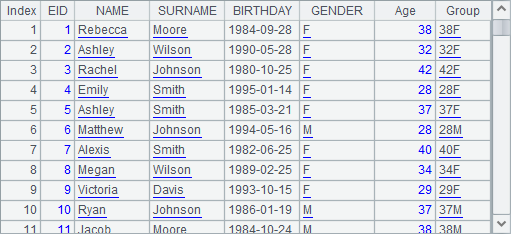
The expression in A3 not only adds two fields to the original sequence at once, but references the the newly-added Age field in the Group field. With derive function, a field can be referenced by a field generated later than it. By the way, in esProc, to concatenate a real number with a string, first the real number should be converted to a string.
Another thing worthy of note is that, like new function, derive function will also create a new table sequence rather than purely add a column to the existing one. Each record will be re-created in the new table sequence during the execution. Thus both derive function and new function are not sufficiently efficient. But the efficiency can be much increased if one executes derive only once to add multiple fields. So the coding method in A2 is better than the step-by-step method in the previous example. Even if some data can’t be known at the beginning, null fields can be generated for them during the execution of derive function and assign values to them later by A.run() function. For example:
|
|
A |
|
1 |
$(demo) select EID,NAME,SURNAME,BIRTHDAY,GENDER from EMPLOYEE |
|
2 |
=A1.derive(age(BIRTHDAY),:FullName) |
|
3 |
>A2.run(FullName=NAME+" "+SURNAME) |
This method is more efficient than the multi-step execution of derive operations because it is unnecessary to re-create the records in the new table sequence and only value assignment is needed.
Similar to new function, derive function can work with @i option, too. When computing a to-be-added column with an expression, a record won’t be added if null value appears.
3.1.4 Creating a TSeq with both new and derive functions
In some cases, a new table sequence requires adding some computed columns but, at the same time, abandoning all the fields of the original table sequence or adjusting the order of the new fields. You can employ the combined effort of the new function and derive function to realize this. For example:
|
|
A |
|
1 |
$(demo) select EID,NAME,SURNAME,BIRTHDAY,GENDER from EMPLOYEE |
|
2 |
=A1.derive(NAME+" "+SURNAME:FullName).new(EID,FullName,GENDER, BIRTHDAY) |
|
3 |
=A1.derive(NAME+" "+SURNAME:FullName) |
|
4 |
=A3.new(EID,FullName,GENDER,BIRTHDAY) |
After FullName is obtained according to the employees’ NAME and SURNAME in A1’s table sequence, NAME and SURNAME are not needed any more. Besides, the fields need to be rearranged. Move FullName forward, for example, as the fields generated by derive function will always come at the end. To do this A2 uses derive function and new function together. A2’s result is as follows:
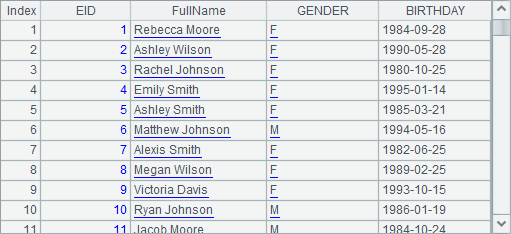
A2 is equivalent to the effect of two-step execution in A3 and A4. Therefore, the new function is actually executed based on the result of executing the derive function, like A3, when they are used consecutively:
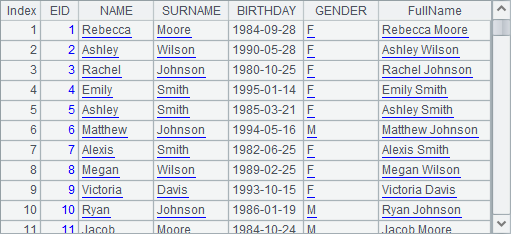
So the new function can not only reference the fields of the original table sequence, like EID, but also the newly-generated field derived through the derive function, such as FullName.
It is more common to first add fields using derive function and then arrange the result using new function when they are used together. But one can also arrange the desired fields first using new function and then generate the computed fields using derive function. For example:
|
|
A |
|
1 |
$(demo) select EID,NAME,SURNAME,BIRTHDAY,GENDER from EMPLOYEE |
|
2 |
=A1.new(EID,NAME+" "+SURNAME:FullName,GENDER, age(BIRTHDAY):Age).derive(string(Age)+GENDER:Group) |
In this example, the new Age field is needed in obtaining the Group field, so A2 first arranges the A1’s table sequence using new function and then computes Group field using derive function. A2’s result is as follows:
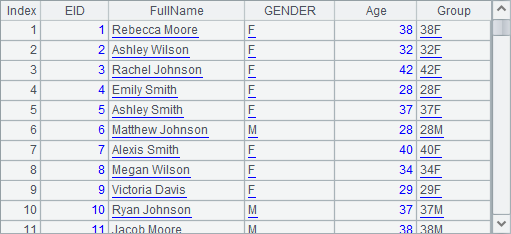
It needs to be made clear that this time derive function is executed based on the result of new function, and thus the derive function can’t reference fields of the original table sequence, like NAME, SURNAME, and etc.