T.group(x:F,…;y:G,…)
Description:
Define a computation, which will group records by comparing the grouping field in each with its next neighbor and perform aggregation over each group, on a pseudo table and return a new pseudo table.
Syntax:
Note:
The function defines a computation on pseudo table T, which will group its records by expression x whose values are those of field F, compute aggregate expression y whose values are those of field G, and returns a new pseudo table consisting of fields F,... G,….
Pseudo table T is ordered by expression x whose values are only compared with their next neighbors, and the result set won’t be sorted again.
Parameter:
|
T |
A pseudo table |
|
x |
Grouping expression |
|
F |
Field name |
|
G |
Aggregation field name |
|
y |
Aggregate expression |
Option:
|
@s |
Cumulative aggregation |
|
@q(x:F,…;x’:F’,…;…) |
Used when parameter T is ordered by x,… and only fields after it need to be sorted; support in-memory sorting |
|
@sq(x:F,…;x’:F’,…;…) |
Only sort without grouping when parameters y:G are absent, and perform cumulative aggregation when the parameters are present; @s works only when @q option is present |
|
@e |
Return a pseudo table consisting of results of expression y; grouping expression x is a field of T and y is function on T; the result of computing y must be one record of T; and y only supports maxp, minp and top@1 functions when it is an aggregate expression |
Return value:
Pseudo table
Example:
|
|
A |
|
|
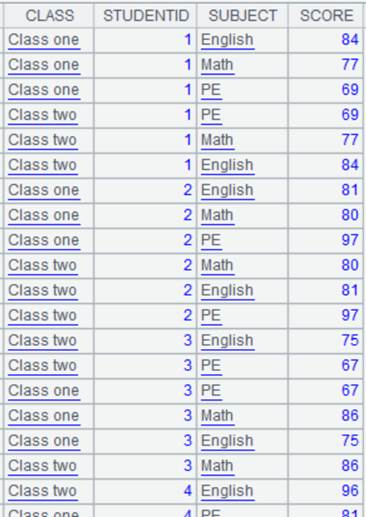
1 |
=create(file).record(["scores-g.ctx"]) |
scores-g.ctx is a composite table file ordered by STUDENTID; its content is as follows:
|
|
2 |
=pseudo(A1) |
Generate a pseudo table from composite table A1. |
|
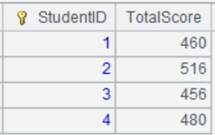
3 |
=A2.group(STUDENTID:StudentID;~.sum(SCORE):TotalScore) |
Define a computation on A2’s pseudo table, which will group pseudo table A2 by STUDENTID and compute total SCORE values in each group, and return a new pseudo table. |
|
4 |
=A3.import() |
Import data from A3’s pseudo table while executing the computation defined on A2’s pseudo table in A3, and return the following pseudo table:
|
|
|
A |
|
|
1 |
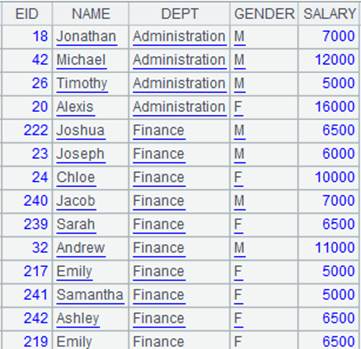
=create(file).record(["emp-g.ctx"]) |
emp-g.ctx is a composite table file ordered by DEPT; its content is as follows:
|
|
2 |
=pseudo(A1) |
Generate a pseudo table from composite table A1. |
|
3 |
=A2.group@q(DEPT;GENDER) |
Define a computation on A2’s pseudo table – as the pseudo table is already ordered by DEPT, the function only sorts by GENDER during grouping – and return a new pseudo table:
|
|
4 |
=A3.cursor().fetch() |
Fetch data from A3’s pseudo table while executing the computation defined on A2’s pseudo table in A3, and return the following pseudo table:
|
|
5 |
=A2.group@qs(DEPT:DEPT;GENDER:GENDER) |
Define a computation on A2’s pseudo table, which will only sort records without grouping since parameters y:G are absent, and return a new pseudo table.
|
|
6 |
=A5.import() |
Import data from A5’s pseudo table while executing the computation defined on A2’s pseudo table in A5, and return the following pseudo table:
|
|
7 |
=A2.group@qs(DEPT:DEPT;GENDER:GENDER;count(GENDER):count) |
Define a computation on A2’s pseudo table, which will Perform cumulative aggregation as parameters y:G are present, and return a new pseudo table.
|
|
8 |
=A7.import() |
Import data from A7’s pseudo table while executing the computation defined on A2’s pseudo table in A7, and return the following pseudo table:
|
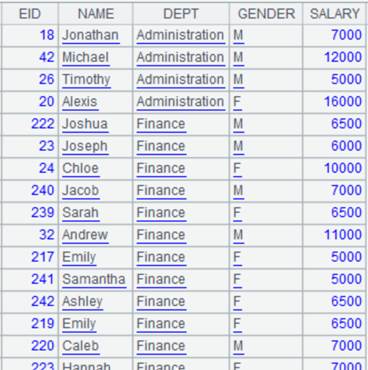
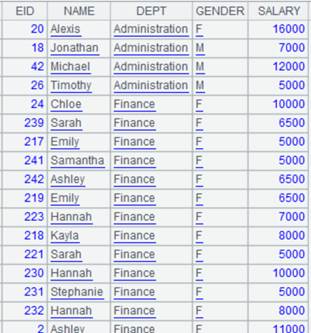
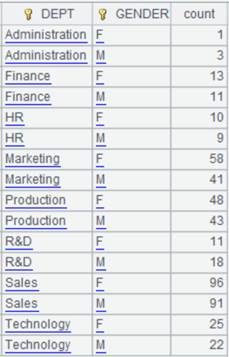
With @e option, return a pseudo table consisting of results of expression y:
|
|
A |
|
|
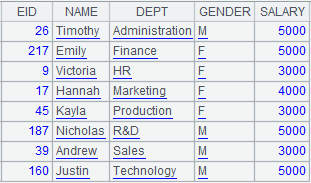
1 |
=create(file).record(["emp-g.ctx"]) |
Below is content of composite table emp-g.ctx:
|
|
2 |
=pseudo(A1) |
Generate a pseudo table from composite table A1. |
|
3 |
=A2.group@e(DEPT;~.minp(SALARY)) |
Define a computation on A2’s pseudo table, which, with @e option, will return a pseudo table consisting of result records of computing minp(SALARY).
|
|
4 |
=A3.fetch().cursor() |
Fetch data from A3’s pseudo table while executing the computation defined on A2’s pseudo table in A3, and return the following pseudo table:
|