groupi()
Here’s how to use groupi() function.
A.groupi(D i ,…)
Description:
Generate a sequence based on a multilayer dimension cell in a data-input sheet.
Syntax:
A.groupi(Di,…)
Note:
Rules of extending a dimension cell in a data-input sheet: When a specific dimension cell is extended vertically or horizontally and if members of the next dimension sequence in the dimension cell (which takes the above dimension cell as the primary cell) to the right of or under the former dimension cell are also sequences, split and extend each member sequence into the nearest copied cell; if the next dimension cell to the right or under it after the first split is also such a one, extend it the same way until the directly next cell is not a dimension cell or the dimension sequence is not a sequence of sequences.
The function is used to generate a dimension sequence whose members are also sequences when a dimension cell in a data-input sheet is extendable and of multilayer. Di is a dimension of a data-input sheet. Column values of D1 are non-duplicate sequences grouped by D1. Column values of D2 are non-duplicate sequences that are the result of grouping each of D1’s sequences by D2. In this way, column values of Di are non-duplicate sequences that are the result of grouping each of Di-1’s sequences by Di.
Option:
|
@o |
Assume that the sequence is ordered, perform a merge by comparing each record with its next neighbor and won’t sort the result set |
Parameter:
|
A |
A sequence |
|
Di |
A data-input sheet’s dimension |
Return value:
A sequence
Example:
|
|
A |
|
|
1 |
=demo.query("select * from employee") |
Return a table sequence.
|
|
2 |
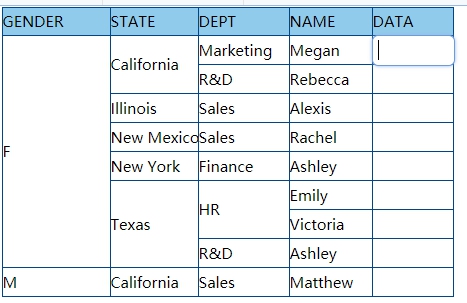
=A1.groupi(GENDER,STATE,DEPT,NAME) |
STATE value in the first record is the non-duplicate states when GENDER is F; the first subsequence [Marketing,Sales] of DEPT value is the non-duplicate departments when GENDER is F and STATE is Alabama; the first subsequence [Lauren] of NAME value is the non-duplicate names when GENDER is F, STATE is Alabama and DEPT is Marketing.
|
|
3 |
=demo.query("select * from employee order by GENDER,STATE,DEPT") |
Return a table sequence and sort it by GENDER,STATE and DEPT.
|
|
4 |
=A3.groupi@o(GENDER,STATE,DEPT,NAME) |
Since A3’s table sequence is already ordered, perform a merge by comparing neighboring records; this gets the same result as A2’s but is faster.
|


The following script handles data processing and generates source data for a data-input sheet:
|
|
A |
|
1 |
=connect("demo") |
|
2 |
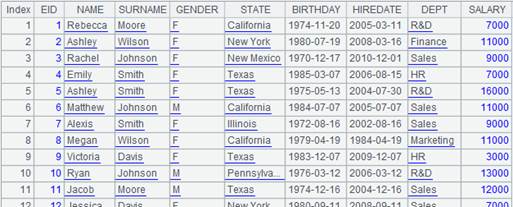
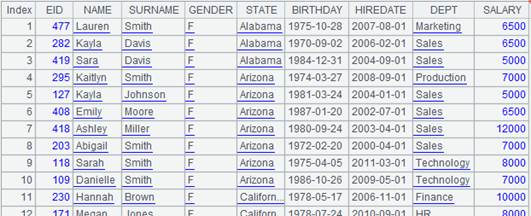
=A1.query("select * from employee where EID <10") |
|
3 |
=a=A2.groupi(GENDER,STATE,DEPT,NAME) |
|
4 |
>A1.close() |
Content of the data-input sheet is as follows:
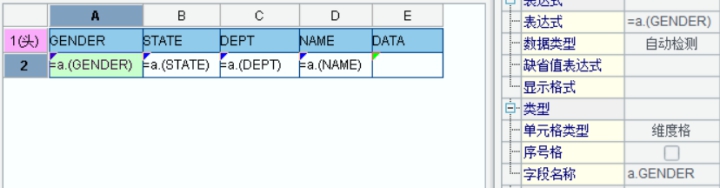
Below is the web preview of the data-input sheet: