groups()
Here’s how to use groups() function.
A. groups()
Description:
Group a table sequence and then get the aggregate result cumulatively.
Syntax:
A.groups(x:F,…;y:G,…)
Note:
The function groups and aggregates table sequence A by expression x to generate a new table sequence with F,.. G… as the fields. Namely, during the traversal through members of A, they will be placed to the corresponding result set one by one while a result set is aggregated cumulatively. Compared with the method of first grouping and then aggregation represented by A.group(x:F,…;y:G,…) function, the function has a better performance.
Option:
|
@o |
Group records by comparing adjacent ones, which is equal to the merging operation, and the result set won’t be sorted |
|
@n |
x gets assigned with group numbers which can be used to define the groups. @n and @o are mutually exclusive |
|
@u |
Do not sort the result set by x. It doesn’t work with @o/@n |
|
@i |
x is a Boolean expression. If the result of x is true, then start a new group. There is only one x |
|
@m |
Use parallel algorithm to handle data-intensive or computation-intensive tasks; no definite order for the records in the result set; can’t be used with @o and @i options |
|
@0 |
Discard the group over which the result of grouping expression x is null |
|
@h |
Used over a grouped table with each group ordered to speed up grouping |
|
@t |
Return an empty table sequence with data structure if the grouping and aggregate operation over the sequence returns null |
|
@z(…;…;n) |
Split the sequence according to groups during parallel computation, and the multiple threads share a same result set; in this case HASH space will not be dynamically adjusted; parameter n is HASH space size, whose value can be default |
|
@e |
Return a table sequence consisting of results of computing function y; expression x is a field of sequence A and y is a function on A; the result of y must be one record of A and y only supports maxp, minp and top@1 when it is an aggregate function |
Parameter:
|
A |
A sequence |
|
x |
Grouping expression |
|
F |
Field name of the result table sequence |
|
y |
y is the function with which A is traversed. When y is an aggregate function, it only supports sum/count/max/min/top/avg/iterate/icount/median/maxp/minp/concat/var. When the function work with iterate(x,a;Gi,…) function, the latter’s parameter Gi should be omitted. When y isn’t an aggregate function, perform calculation over only the first record in each group |
|
G |
Summary field name in the result table sequence |
Return value:
Post-grouping table sequence
Example:
|
|
A |
|
|
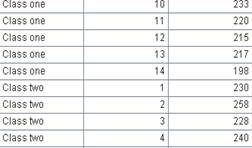
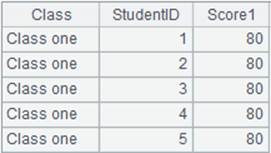
1 |
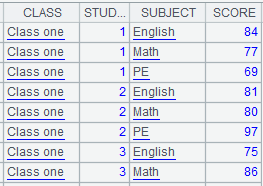
=demo.query("select * from SCORES where CLASS = 'Class one'") |
|
|
2 |
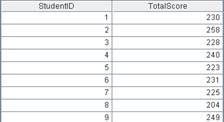
=A1.groups(STUDENTID:StudentID;sum(SCORE):TotalScore) |
Group by a single field. |
|
3 |
=demo.query("select * from SCORES") |
|
|
4 |
=A3.groups(CLASS:Class,STUDENTID:StudentID;sum(SCORE):TotalScore) |
group by multiple fields. |
|
5 |
=A3.groups@m(STUDENTID:StudentID;sum(SCORE):TotalScore) |
Use @m option to increase performance of big data handling. |
|
6 |
=A3.groups@o(STUDENTID:StudentID;sum(SCORE):TotalScore) |
Only compare and merge with the neighboring element, and the result set is not sorted. |
|
7 |
=demo.query("select * from STOCKRECORDS where STOCKID<'002242'") |
|
|
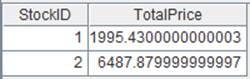
8 |
=A7.groups@n(if(STOCKID=="000062",1,2):StockID;sum(CLOSING):TotalPrice) |
The value of x is the group ordinal number. |
|
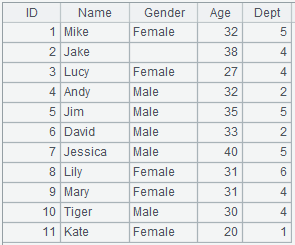
9 |
=demo.query("select * from EMPLOYEE") |
|
|
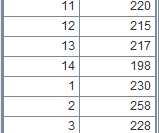
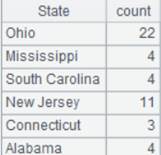
10 |
=A9.groups@u(STATE:State;count(STATE):TotalScore) |
Do not sort result set by the sorting field. |
|
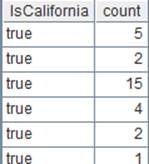
11 |
=A9.groups@i(STATE=="California":IsCalifornia;count(STATE):count) |
Start a new group when STATE=="California". |
|
12 |
=A3.groups(CLASS:Class,STUDENTID:StudentID;iterate(~~*2,10): Score1) |
Perform iterate operation within each group. |
|
13 |
=file("D:\\Salesman.txt").import@t() |
|
|
14 |
=A13.groups@0(Gender:Gender;sum(Age):Total) |
Discard groups where Gender values are nulls. |
|
15 |
=file("D:/emp10.txt").import@t() |
For data file emp10.txt, every 10 records are ordered by DEPT.
|
|
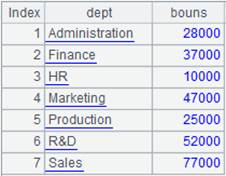
16 |
=A15.groups@h(DEPT:dept;sum(SALARY):bouns) |
A15 is grouped and ordered by DEPT, for which @h option is used to speed up grouping.
|
|
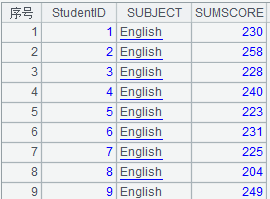
17 |
=A1.groups(STUDENTID:StudentID;SUBJECT,sum(SCORE):SUMSCORE) |
Parameter y isn’t an aggregate function, so the function performs operation over the first record.
|
|
18 |
=demo.query("select * from SCORES where CLASS = 'Class three'") |
Return an empty table sequence. |
|
19 |
=A18.groups@t(STUDENTID:StudentID;sum(SCORE):TotalScore) |
Return an empty table sequence with the data structure.
|
|
|
A |
|
|
1 |
=demo.query("select * from SCORES") |
|
|
2 |
=A1.groups@z(STUDENTID:StudentID;sum(SCORE):TotalScore;5) |
Split A1’s sequence according to groups during parallel computation; the hash space size is 5. |
|
|
A |
|
|
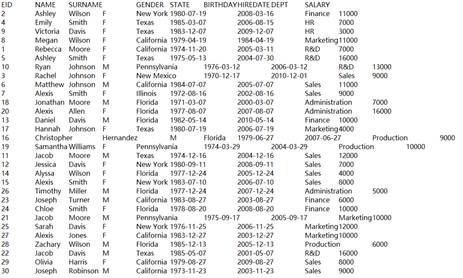
1 |
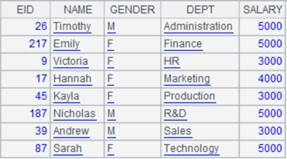
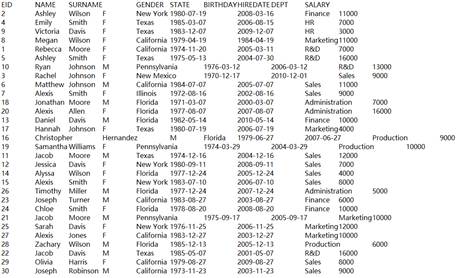
=demo.query("select EID,NAME,GENDER,DEPT,SALARY from employee") |
|
|
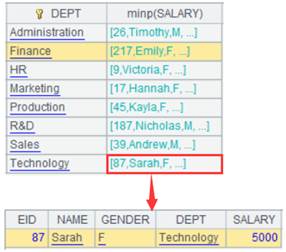
2 |
=A1.groups(DEPT;minp(SALARY)) |
Execute aggregate function minp() and return A3’s records. |
|
3 |
=A1.groups@e(DEPT;minp(SALARY)) |
Return a table sequence consisting of result records of computing minp(SALARY). |
Related function:
ch.groups ()
Description:
Group records in a channel.
Syntax:
ch.groups(x:F,…;y:G…;n)
Note:
The function groups records in channel ch according to grouping expression x, by which the records are ordered, to get a channel having F,...G,… fields.
Sort records in the new channel by x. Values of G field are the results of computing expression y over each group. It aims to fetch the grouping result set from the channel.
Option:
|
@n |
With the option the value of expression x is a group number, which points to the desired group |
|
@u |
Won’t sort the resulting set by expression x; the option and @n are mutually exclusive |
Parameter:
|
ch |
Channel |
|
x |
Grouping expression, by which an aggregation over the whole grouped set is performed if x:F is omitted. In that case the semicolon “;” should not be omitted |
|
F |
Field names of the resulting table sequence |
|
y |
An aggregate function on channel ch, which only supports sum/count/max/min/top/avg/iterate/concat/var; the parameter Gi should be given up if function iterate(x,a;Gi,…) is used |
|
G |
The aggregate fields in the resulting table sequence |
Return value:
Channel
Example:
|
|
A |
|
|
1 |
=demo.cursor("select * from EMPLOYEE ") |
|
|
2 |
=channel() |
Create a channel. |
|
3 |
=channel() |
Create a channel. |
|
4 |
=channel() |
Create a channel. |
|
5 |
=channel() |
Create a channel. |
|
6 |
=A1.push(A2,A3,A4,A5) |
Be ready to push the data in A1’s cursor into channel A2, A3 and A5, but the action needs to wait. |
|
7 |
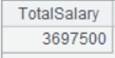
=A2.groups(;sum(SALARY):TotalSalary) |
As x:F is omitted, calculate the sum of salaries of all employees. |
|
8 |
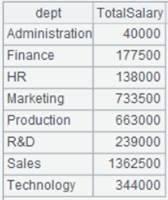
=A3.groups(DEPT:dept;sum(SALARY):TotalSalary) |
Group and sort records by DEPT field. |
|
9 |
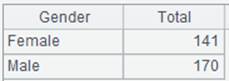
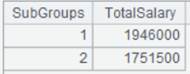
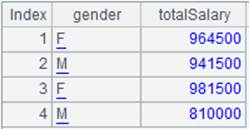
=A4.groups@n(if(GENDER=="F",1,2):SubGroups;sum(SALARY):TotalSalary) |
The value of x is group number; put records where GENDER is “F” into the first group and others into the second group, and then aggregate each group. |
|
10 |
=A5.groups@u(STATE:State;count(STATE):count) |
Won’t sort the resulting set by grouping field |
|
11 |
A1.select(month(BIRTHDAY)==2) |
|
|
12 |
A11.fetch() |
Attach a fetch operation to A11’s cursor. |
|
13 |
=A2.result() |
|
|
14 |
=A3.result() |
|
|
15 |
=A4.result() |
|
|
16 |
=A5.result() |
|
cs.gr oups()
Description:
Group records in a cluster cursor, sort them by the grouping field and perform aggregation over each group and add each aggregate to the result set.
Syntax:
cs.groups(x:F,…;y:G…;n)
Note:
The function groups records in a cluster cursor by expression x, sorts result by the grouping field, and calculates the aggregate value on each group.
This creates a new table sequence consisting of fields F,...G,… and sorted by the grouping field x.The G field gets values by computing y on each group.
Option:
|
@c |
Perform the group operation over data in every node and compose the result sets into a cluster in-memory table in the segmentation way of the cursor; support a cluster dimension table |
Parameter:
|
cs |
Records in a cluster cursor |
|
x |
Grouping expression; if omitting parameters x:F, aggregate the whole set; in this case, the semicolon “;” must not be omitted |
|
F |
Field name in the result table sequence |
|
y |
An aggregate function on cs, which only supports sum/count/max/min/top /avg/iterate/concat/var; when the function works with iterate(x,a;Gi,…) function, the latter’s parameter Gi should be omitted |
|
G |
Aggregate field name in the result table sequence |
|
n |
The specified maximum number of groups; stop executing the function when the number of data groups is bigger than n to prevent memory overflow; the parameter is used in scenarios when it is predicted that data will be divided into a large number of groups that are greater than n |
Return value:
A table sequence/cluster in-memory table
Example:
|
|
A |
|
|
1 |
=file("emp1.ctx","192.168.0.111:8281") |
Below is emp1.ctx:
|
|
2 |
=A1.open() |
Open a cluster composite table. |
|
3 |
=A2.cursor() |
Return a cluster cursor. |
|
4 |
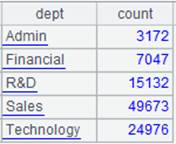
=A3.groups(Dept:dept;count(Name):count) |
Group data by DEPT and perform aggregation. |
|
|
A |
|
|
1 |
[192.168.0.110:8281,192.168.18.143:8281] |
|
|
2 |
=file("emp.ctx":[1,2], A1) |
|
|
3 |
=A2. open () |
Open a cluster composite table. |
|
4 |
=A3.cursor() |
Create a cluster cursor. |
|
5 |
=A4.groups(GENDER:gender;sum(SALARY):totalSalary) |
Group data by GENDER and perform aggregation and return result as a table sequence.
|
|
6 |
=A3.cursor() |
|
|
7 |
=A6.groups@c(GENDER:gender;sum(SALARY):totalSalary).dup() |
Retain the way of segmentation of the distributed cursor and return a cluster in-memory table.
|
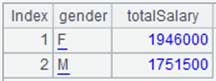
Related function:
cs.groups()
Description:
Group records in a cursor.
Syntax:
cs.groups(x:F,…;y:G…)
Note:
The function groups records in a cluster cursor by expression x, sorts result by the grouping field, and calculates the aggregate value on each group. This creates a new table sequence consisting of fields F,...G,… and sorted by the grouping field x. The values of F field are the value of x field of the first record in each group and G field gets values by computing yon each group. The aggregation over a cluster cursor will first be performed by the main process on the local machine and the result will then be returned to the machine that initiates the invocation; the process is called reduce.
Option:
|
@n |
The value of grouping expression is group number used to locate the group; you can use n to specify the number of groups and generate corresponding number of zones first |
|
@u |
Do not sort the result set by the grouping expression; it doesn’t work with @n |
|
@o |
Compare each record only with its neighboring record to group, which is equivalent to the merge operation, and won’t sort the result set |
|
@i |
With this option, the function only has one parameter x that is a Boolean expression; start a new group if its result is true |
|
@h |
Used over a grouped table with each group ordered to speed up grouping |
|
@0 |
Discard groups on which expression x gets empty result |
|
@t |
When empty data is obtained from the cursor, the function returns an empty table sequence having only the data structure |
|
@z(…;…;n) |
Split the sequence according to groups during parallel computation, and the multiple threads share a same result set; in this case HASH space will not be dynamically adjusted; parameter n is HASH space size, whose value can be default |
|
@e |
Return a table sequence consisting of results of computing function y; expression x is a field of cursor cs and y is a function on cs; the result of y must be one record of cs and y only supports maxp, minp and top@1 when it is an aggregate function |
Parameter:
|
cs |
Records in a cursor |
|
x |
Grouping expression; if omitting parameters x:F, aggregate the whole set; in this case, the semicolon “;” must not be omitted |
|
F |
Field name in the result table sequence |
|
y |
An aggregate function on cs, which only supports sum/count/max/min/top/avg/iterate/concat/var; when the function works with iterate(x,a;Gi,…) function, the latter’s parameter Gi should be omitted |
|
G |
Aggregate field name in the result table sequence |
Return value:
Table sequence
Example:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES where CLASS = 'Class one'") |
|
|
2 |
=A1.groups(;sum(SCORE):TotalScore) |
As parameters x:F absent, calculate the total score of all students. |
|
3 |
=demo.cursor("select * from FAMILY") |
|
|
4 |
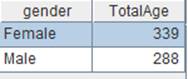
=A3.groups(GENDER:gender;sum(AGE):TotalAge) |
Group and order data by specified fields. |
|
5 |
=demo.cursor("select * from STOCKRECORDS where STOCKID<'002242'") |
|
|
6 |
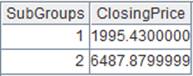
=A5.groups@n(if(STOCKID=="000062",1,2):SubGroups;sum(CLOSING):ClosingPrice) |
The value of grouping expression is group number; put records whose STOCKID is “000062” to the first group and others to the second group; and meanwhile aggregate each group. |
|
7 |
=demo.cursor("select * from EMPLOYEE") |
|
|
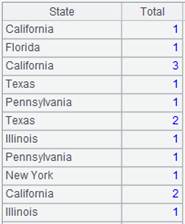
8 |
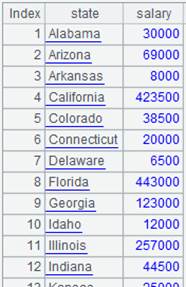
=A7.groups@u(STATE:State;count(STATE):Total) |
The result set won’t be sorted by the grouping field. |
|
9 |
=demo.cursor("select * from EMPLOYEE") |
|
|
10 |
=A9.groups@o(STATE:State;count(STATE):Total) |
Compare each record with its next neighbor and won’t sort the result set.
|
|
11 |
=demo.cursor("select * from EMPLOYEE") |
|
|
12 |
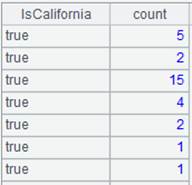
=A11.groups@i(STATE=="California":IsCalifornia;count(STATE):count) |
Start a new group if the current record meets the condition STATE=="California". |
|
13 |
=file("D:/emp10.txt").cursor@t() |
For
data file emp10.txt, every 10
records are ordered by DEPT |
|
14 |
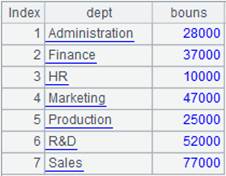
=A13.groups@h(DEPT:DEPT;sum(SALARY):bouns) |
As A13 is grouped and ordered by DEPT, use @h option to speed up grouping.
|
|
15 |
=demo.query("select * from employee") |
|
|
16 |
=A15.cursor@m(3) |
Return a multicursor. |
|
17 |
=A16.groups(STATE:state;sum(SALARY):salary) |
Group the multicursor with groups function.
|
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES where CLASS = 'Class three'") |
|
|
2 |
=A1.groups@t(STUDENTID:StudentID;sum(SCORE):TotalScore) |
Return an empty table sequence with the original data structure.
|
|
3 |
=demo.cursor("select * from DEPT") |
Below is content of DEPT table:
|
|
4 |
=A3.groups@0(FATHER) |
Discard groups on which Father field expression gets empty value.
|
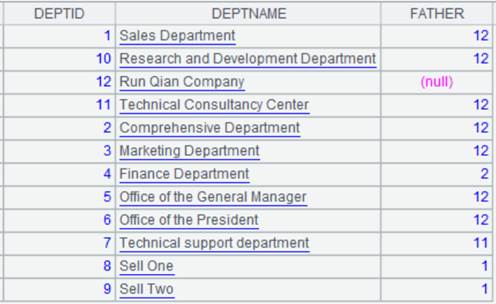

Use @z option to enable parallel processing:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES") |
|
|
2 |
=A1.groups@z(STUDENTID:StudentID;sum(SCORE):TotalScore;5) |
Split A1’s sequence according to groups during parallel computation; HASH space size is 5. |
Use @e option to return a table sequence consisting of results of computing function y:
|
|
A |
|
|
1 |
=demo.cursor("select * from SCORES") |
|
|
2 |
=A1.groups@e(SUBJECT;maxp(SCORE)) |
Return a table sequence consisting of result records of computing maxp(SCORE) . |
T.groups()
Description:
Group records in a pseudo table.
Syntax:
T. groups(x:F,…;y:G…;n)
Note:
The function groups records in a pseudo table by expression x, sorts result by the grouping field, and perform an aggregate operation on each group.
This creates a new table sequence consisting of fields F,...G,… and sorted by the grouping field x. G field gets values by computing aggregate function y on each group.
Option:
|
@n |
The value of grouping expression is group number used to locate the group; you can use n to specify the number of groups and generate corresponding number of zones first |
|
@u |
Do not sort the result set by the grouping expression; it doesn’t work with @n |
|
@o |
Compare each record only with its neighboring record to group, which is equivalent to the merge operation, and won’t sort the result set |
|
@i |
With this option, the function only has one parameter x that is a Boolean expression; start a new group if its result is true |
|
@h |
Used over a grouped table with each group ordered to speed up grouping |
|
@b |
Enable returning a result set containing aggregates only without group-level data |
|
@v |
Store the composite table in the column-wise format when loading it the first time, which helps to increase performance |
Parameter:
|
T |
A pseudo table |
|
x |
Grouping expression; if omitting parameters x:F, aggregate the whole set; in this case, the semicolon “;” must not be omitted |
|
F |
Field name in the result table sequence |
|
y |
An aggregate function on T, which only supports sum/count/max/min/top/avg/iterate/concat/var; when the function works with iterate(x,a;Gi,…) function, the latter’s parameter Gi should be omitted |
|
G |
Aggregate field name in the result table sequence |
|
n |
The specified maximum number of groups; stop executing the function when the number of data groups is bigger than n to prevent memory overflow; the parameter is used in scenarios when it is predicted that data will be divided into a large number of groups that are greater than n |
Return value:
Pseudo table
Example:
|
|
A |
|
|
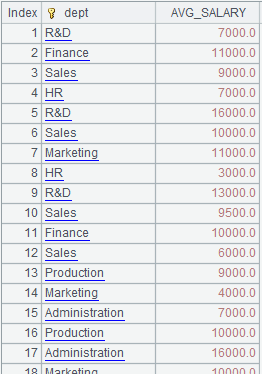
1 |
=create(file).record(["D:/file/pseudo/empT.ctx"]) |
|
|
2 |
=pseudo(A1) |
Generate a pseudo table. |
|
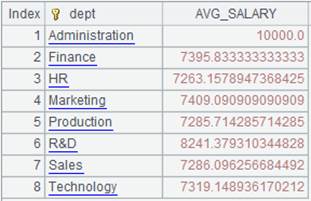
3 |
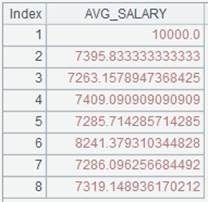
=A2.groups(DEPT:dept;avg(SALARY):AVG_SALARY) |
Group records in A2’s pseudo table by DEPT field, calculate average of SALARY in each group – which is the aggregate method, and return result as a table sequence made up of dept field, and AVG_SALARY field and sorted by dept.
|
|
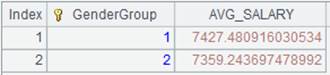
4 |
=A2.groups@n(if(GENDER=="F",1,2):GenderGroup;avg(SALARY):AVG_SALARY) |
Devide recrods of A2’s pseudo table into two groups according to whether GENDER is F, and calculate average SALARY in each group.
|
|
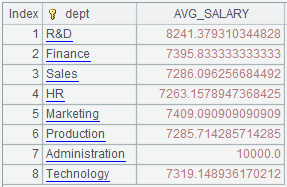
5 |
=A2.groups@u(DEPT:dept;avg(SALARY):AVG_SALARY) |
With @u option, the grouping result won’t be sorted.
|
|
6 |
=A2.groups@o(DEPT:dept;avg(SALARY):AVG_SALARY) |
Withe @o option, compare each record with its next neighbor and won’t sort the result set.
|
|
7 |
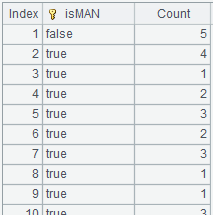
=A2.groups@i(GENDER=="M":isMAN;count(EID):Count) |
Start a new group if the current record meets the condition GENDER=="M".
|
|
8 |
=A2.groups@b(DEPT:dept;avg(SALARY):AVG_SALARY) |
With @b option, return only a column of aggregates without group data.
|