Edit result
After a
result set is named, we can perform operations on it, such as filtering, sorting,
grouping, set operations, add, delete, modify, and export. For example, we
click ![]() to rename the above result set Emp:
to rename the above result set Emp:
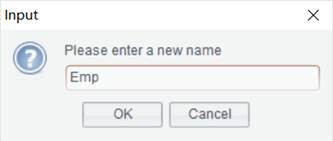
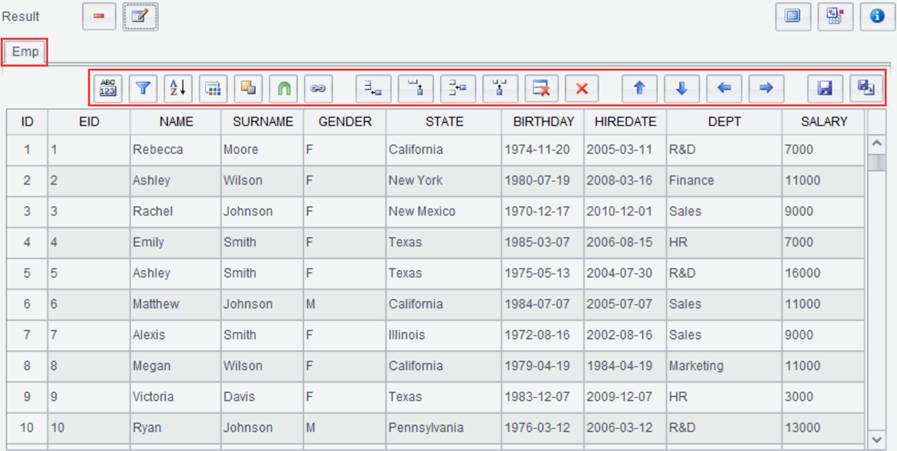
Click “OK” to get the following interface displaying the result set:
Edit data
This section explains common operations on a result set, such as add, delete, and modify.
Ø Append row
Click ![]() to add a row after the last row of the result
set.
to add a row after the last row of the result
set.
Ø Append column
Click ![]() to add a column after the last column of
the result set.
to add a column after the last column of
the result set.
Ø Insert row
Click ![]() to insert a row before a selected row or
cell.
to insert a row before a selected row or
cell.
Ø Insert column
Click ![]() to insert a column before a selected
column or cell.
to insert a column before a selected
column or cell.
Ø Delete row
Click ![]() to delete one or more selected rows.
to delete one or more selected rows.
Ø Delete column
Click ![]() to delete one or more selected columns.
to delete one or more selected columns.
Ø Shift row up
Click ![]() to move up one or more selected rows.
to move up one or more selected rows.
Ø Shift row down
Click ![]() to move down one or more selected rows.
to move down one or more selected rows.
Ø Shift column left
Click ![]() to move the current column left.
to move the current column left.
Ø Shift column right
Click ![]() to move the current column right.
to move the current column right.
Ø Modify
Select a cell and double click it to modify data in the cell.
Ø Copy
Select one or more rows, right click them, and select copy option to copy the selected row(s) to clipboard.
Ø Cut
Select one or more rows, right click them, and select cut option to cut the selected row(s).
Ø Paste
Select one or more rows, right click to select paste option to paste data on the clipboard to the current position. Note that the action requires that data structure on the clipboard be the same as that of the current table.
Complex computation
This section explains how to perform complex computations on data, such as filtering, sorting and grouping.
Ø Computed column
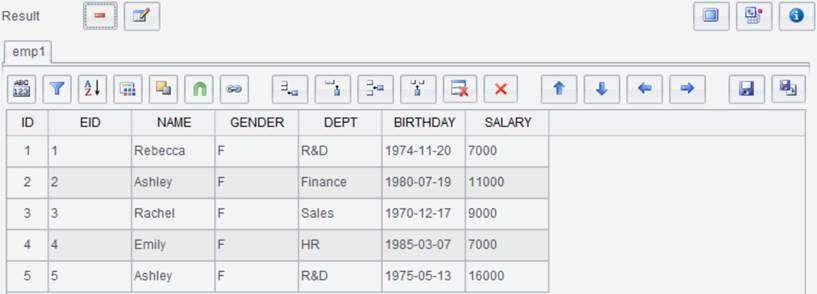
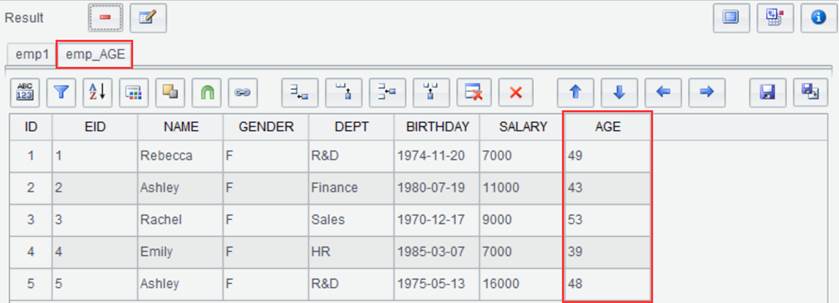
We can add user-defined columns to an existing result set through this “Computed column” functionality and generate a new result set. To add columns AGE to the following emp1 result set and generate new result set emp_AGE, for example:
On the result set page, click ![]() or right-click the result set
data to select a computed column and get into the configuration window:
or right-click the result set
data to select a computed column and get into the configuration window:
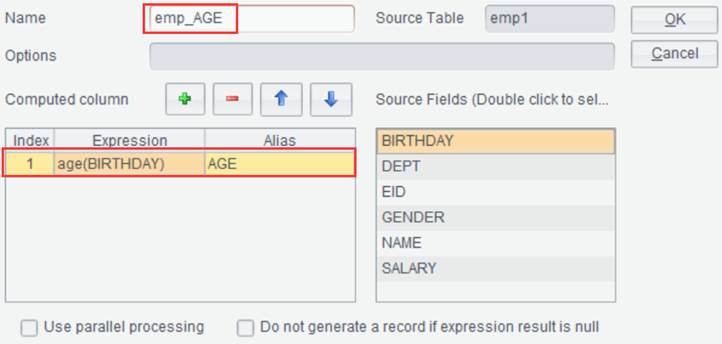
【Use parallel processing】Use the parallel processing to increase performance when the computation is complex and involves a huge volume of data; data won’t be computed in a certain order.
【Do not generate a record if expression result is null】Do not generate a corresponding record when the result of computing the specified expression is null.
Click ![]() to add a new column, whose expression
is age(BIRTHDAY) and alias is AGE and that generates a new result set named
emp_AGE. Click “OK” and generate new result set emp_AGE as follows:
to add a new column, whose expression
is age(BIRTHDAY) and alias is AGE and that generates a new result set named
emp_AGE. Click “OK” and generate new result set emp_AGE as follows:
Ø Filter data
To perform filtering on one or more fields, click ![]() or right click a result set to choose
“Filter data”, and select records according to the specified filter expression.
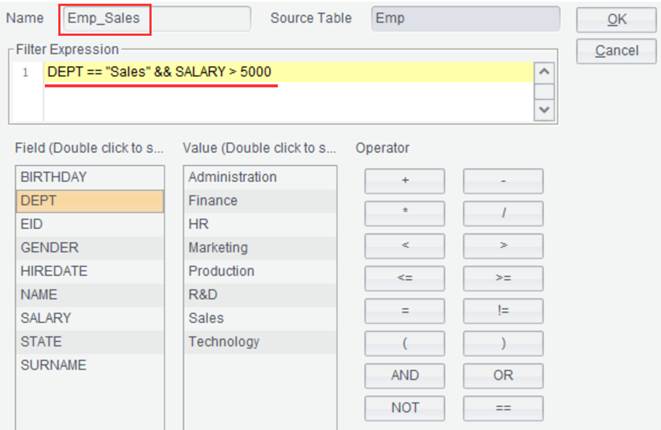
To get records employees in sales department whose salary are above 5,000 from
result set Emp, the filter expression is DEPT == "Sales" &&
SALARY > 5000 and the result set name is set as Emp_Sales, as shown
below:
or right click a result set to choose
“Filter data”, and select records according to the specified filter expression.
To get records employees in sales department whose salary are above 5,000 from
result set Emp, the filter expression is DEPT == "Sales" &&
SALARY > 5000 and the result set name is set as Emp_Sales, as shown
below:
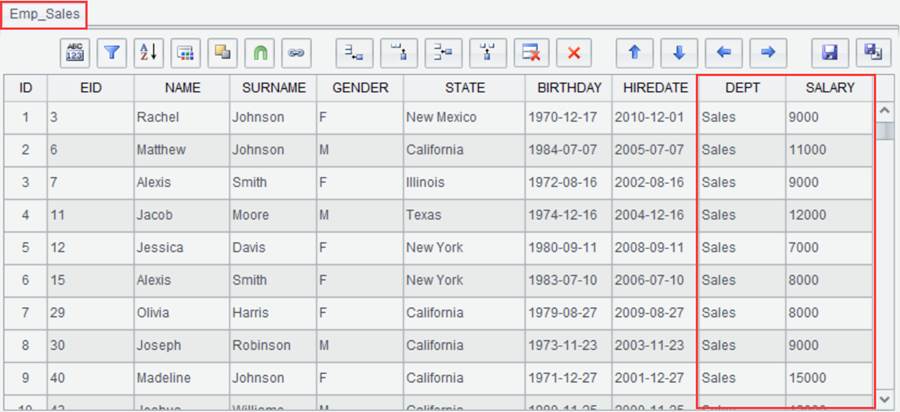
Click “OK” and generate new result set Emp_Sales as follows:
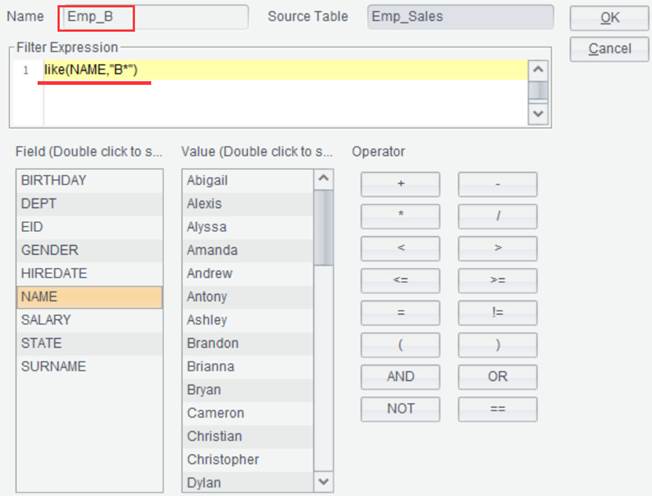
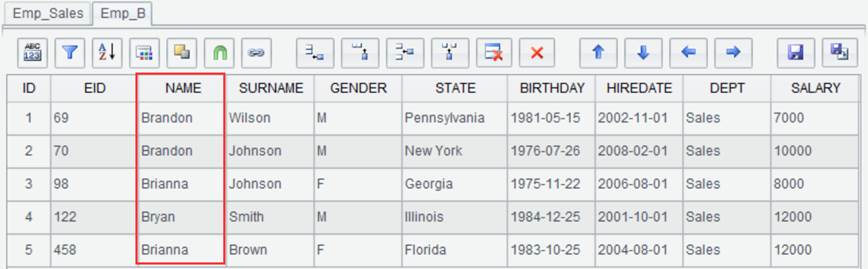
In a filter expression, we can also use an esProc function besides operators. To further filter the above result set Emp_Sales to get records of employees whose names start with letter B, the filter expression is like(NAME,"B*") and result set name is Emp_B, as shown below:
Click “OK” and we get new result set Emp_B as follows:
Ø Sort data
On the “Result” tab, click “Sort data” button ![]() or right-click the result set
data to select “Sort data” and set the sorting field and sorting direction to
display data in the result set in a certain order. To sort result set emp
by HIREDAE in descending order and by NAME in ascending order and name the
result set after sorting Emp_sort, for example:
or right-click the result set
data to select “Sort data” and set the sorting field and sorting direction to
display data in the result set in a certain order. To sort result set emp
by HIREDAE in descending order and by NAME in ascending order and name the
result set after sorting Emp_sort, for example:
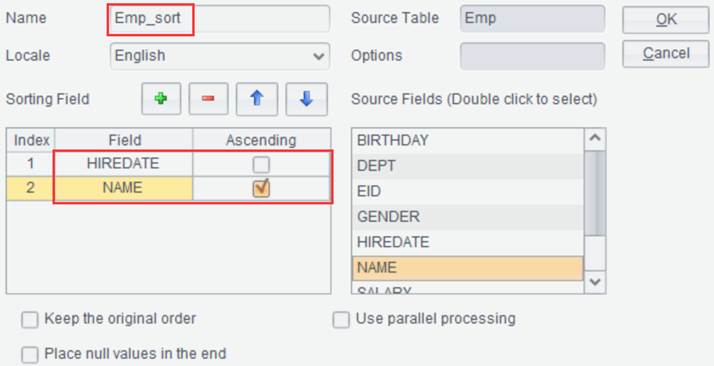
【Keep the original order】Perform sorting on multilevel data by the specified field while keeping the original order, that is, sort data according to positions records appear for the first time.
【Use parallel processing】Use parallel processing to increase performance when the computation is complex and involves a huge volume of data.
【Place null values in the end】Put records where the sorting field values are null in the end.
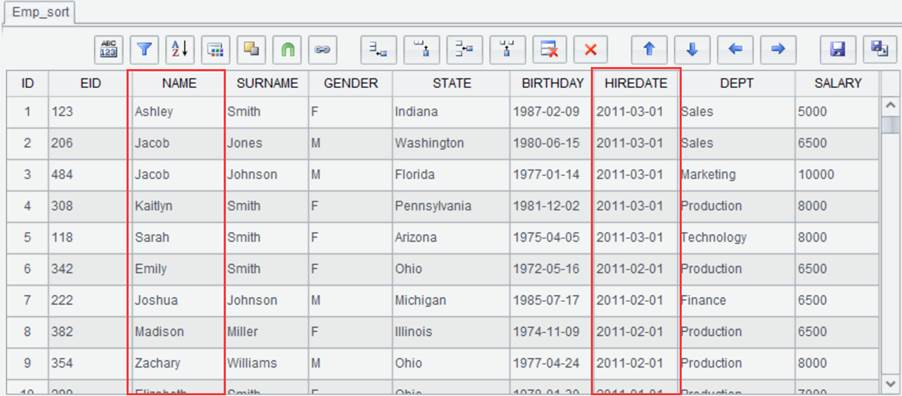
Click “OK” to generate new result set Emp_sort as follows:
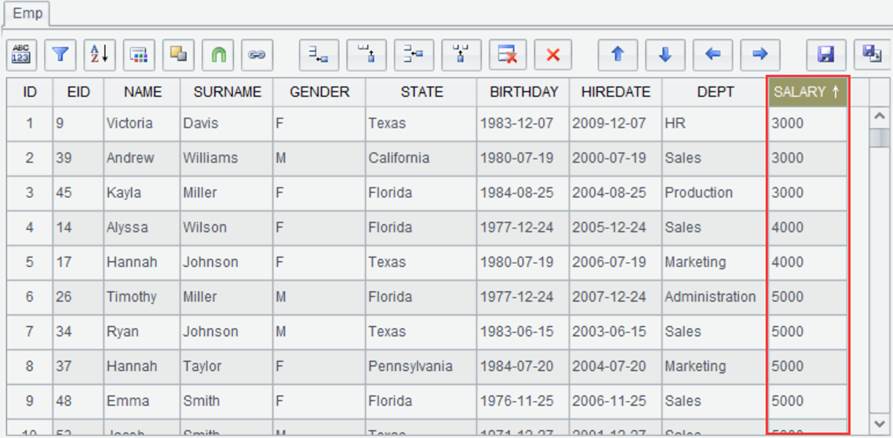
We can also double click a field on the table header to sort the current column. To sort result set Emp by SALARY, double click SALARY field to sort values in ascending order:
Double click SALARY field again to sort values in descending order. We can also drag field names to change order of fields.
Ø Select fields
On the “Result” tab, click “Select fields” button ![]() or right-click result set data
to select fields. This lets us compute the specified expression on certain
fields of the result set to generate a new result set. For example, select EID,
NAME, SURNAME, HIREDATE and SALARY from data set Emp, join up NAME and
SURNAME to form NAME field, compute hire duration according to HIREDATE, and
correspond each EID with two records, which are the original salary SALARY and
the SALARY value after 50% salary increase:
or right-click result set data
to select fields. This lets us compute the specified expression on certain
fields of the result set to generate a new result set. For example, select EID,
NAME, SURNAME, HIREDATE and SALARY from data set Emp, join up NAME and
SURNAME to form NAME field, compute hire duration according to HIREDATE, and
correspond each EID with two records, which are the original salary SALARY and
the SALARY value after 50% salary increase:
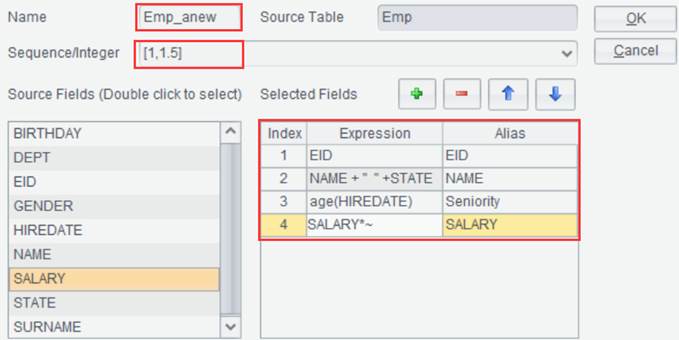
【Sequence/Integer】Optional. Suppose the content to-be-entered is parameter X, then in the selected fields expression we can use “~” to reference X, which can be a sequence or an integer. When it is an integer, it can be understood as to(X), which means performing X round of computations on the result set.
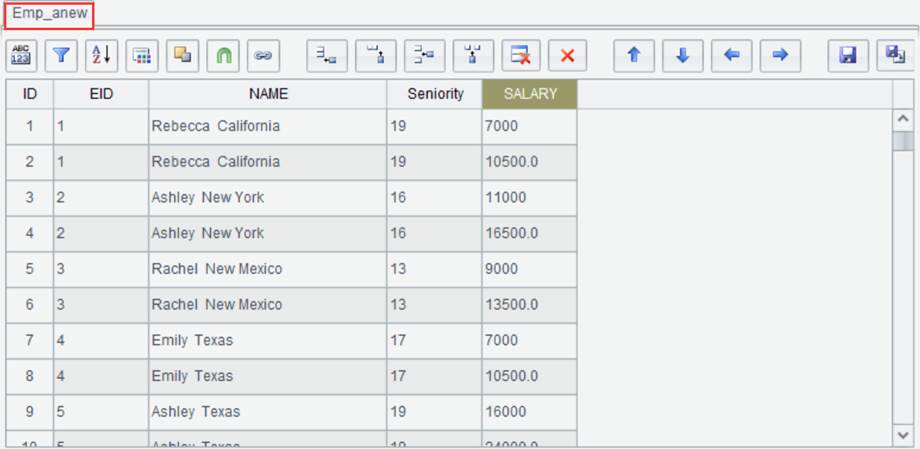
Click “OK” and generate a new result set Emp_anew as follows:
Ø Group data
On the “Result” tab, click “Group data” button ![]() or right-click result set data
to select “Group data”. This lets us to perform grouping & aggregation on a
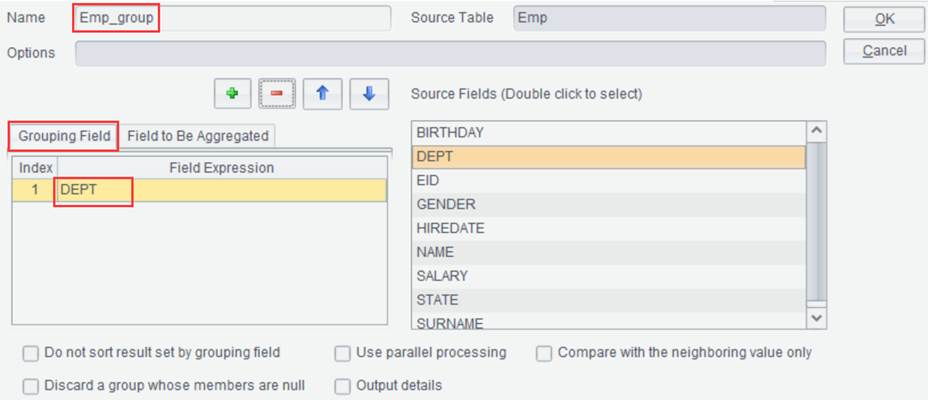
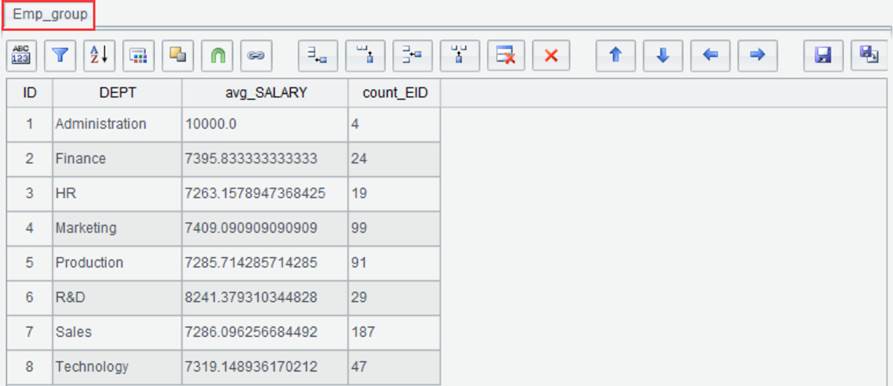
result set. For example, group result set Emp by DEPT field and compute
average salary and the number of employees in each group:
or right-click result set data
to select “Group data”. This lets us to perform grouping & aggregation on a
result set. For example, group result set Emp by DEPT field and compute
average salary and the number of employees in each group:
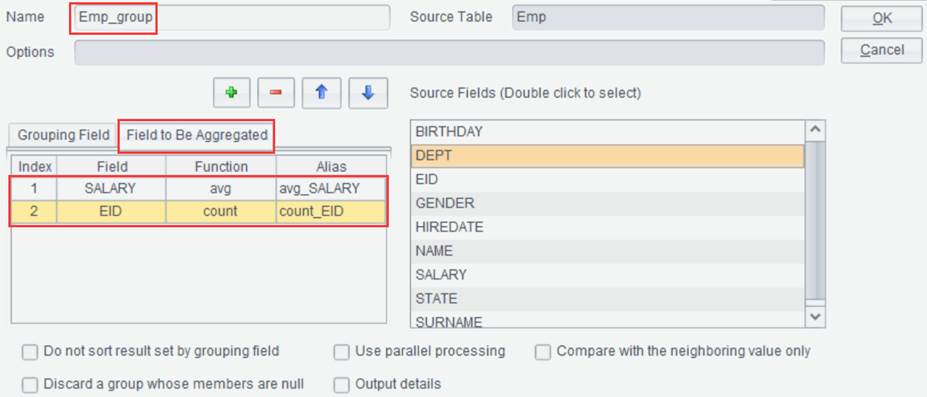
【Do not sort result set by grouping field】Do not sort the result set according to the selected grouping field.
【Use parallel processing】Use parallel processing to increase performance when the computation is complex and involves a huge volume of data.
【Compare with the neighboring value only】Compare value of the specified field with that of the directly next record, which amounts to merge, and won’t sort the result set.
【Discard a group whose members are null】Delete a group on which result of computing the grouping field is null.
【Output details】Add a details field to store records before each group is summarized.
Click “OK” and generate a new result set Emp_group as follows:
Ø Set operations
On the “Result” tab, click “Set operations” button ![]() or right-click result set data
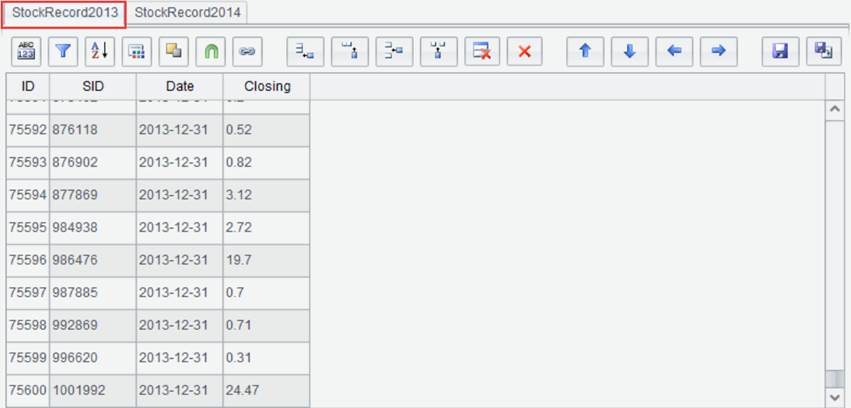
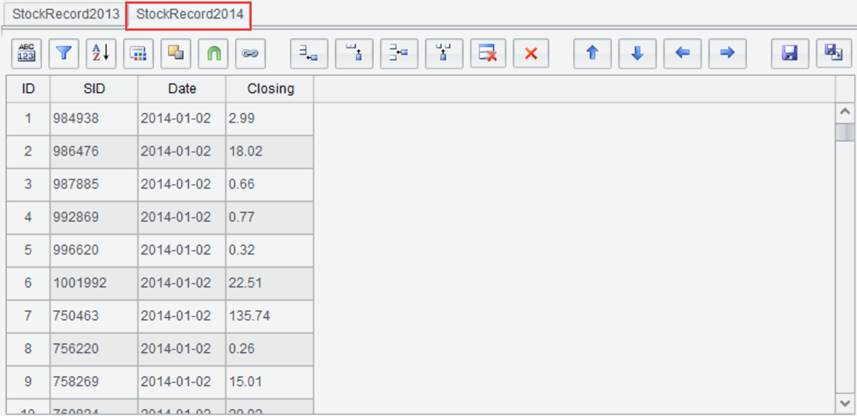
to select “Set operations”. For example, we have result sets StockRecord2013
and StockRecord2014, and trying to union them. Below are contents of the
two result sets:
or right-click result set data
to select “Set operations”. For example, we have result sets StockRecord2013
and StockRecord2014, and trying to union them. Below are contents of the
two result sets:
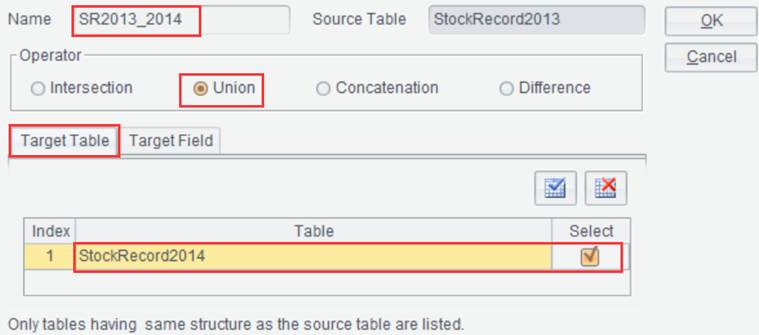
Click ![]() on the interface of result set StockRecord2013
and enter the set operations configuration interface:
on the interface of result set StockRecord2013
and enter the set operations configuration interface:
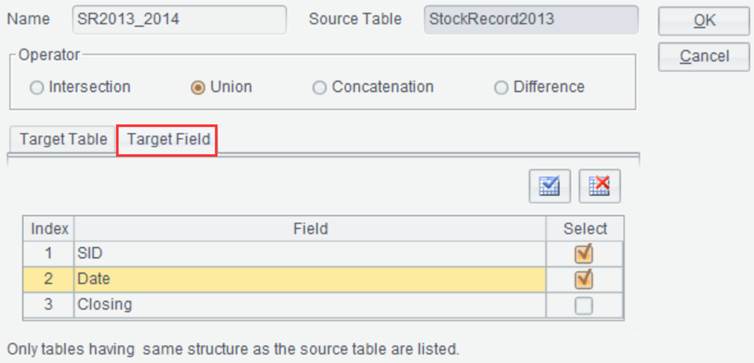
Click “OK” and generate new result set SR2013_2014 as follows:
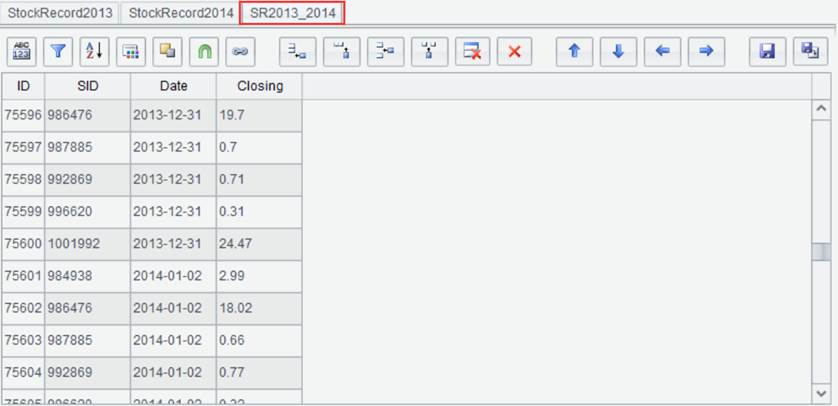
Ø Data association
On the “Result” tab, click “Join” button ![]() or right-click result set data
to select “Join” to associate data in multiple result sets through the join
fields.
or right-click result set data
to select “Join” to associate data in multiple result sets through the join
fields.
Suppose there are two result sets STATECAPITAL and STATENAME, perform an inner join on the two through STATEID field:
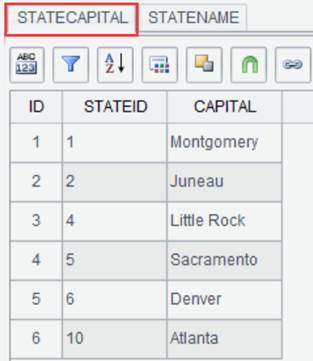
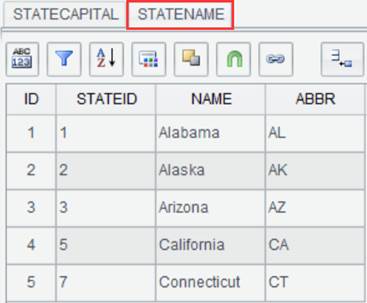
Click ![]() on the interface of result set STATECAPITAL
and enter the data association configuration interface:
on the interface of result set STATECAPITAL
and enter the data association configuration interface:
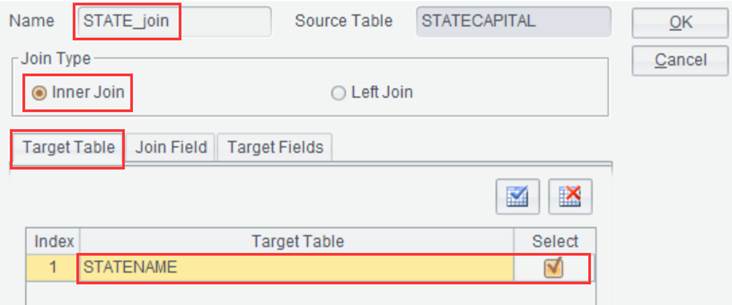
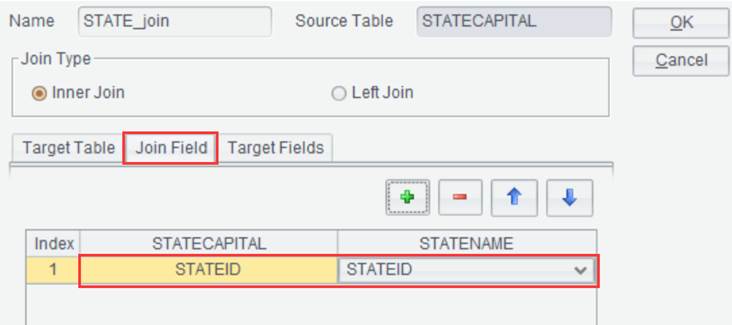
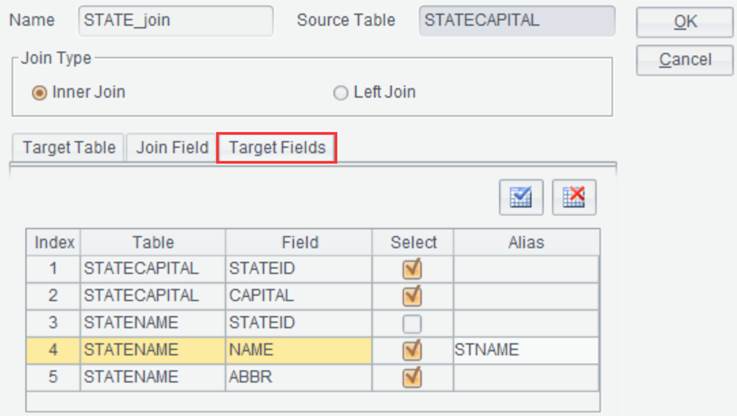
Click “OK” and generate new result set STATE_join as follows:
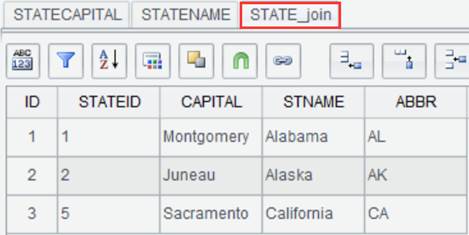
Save data
This section explains how to save an edited result to a file.
Ø Save as text
Click ![]() and we can save the current result set as
a text file of txt fomart.
and we can save the current result set as
a text file of txt fomart.
Ø Export to file
Click ![]() and we can export the current result set
as file of a certain format. Supported file formats include ctx, btx, txt, csv,
and xlsx. Below is the export interface:
and we can export the current result set
as file of a certain format. Supported file formats include ctx, btx, txt, csv,
and xlsx. Below is the export interface:
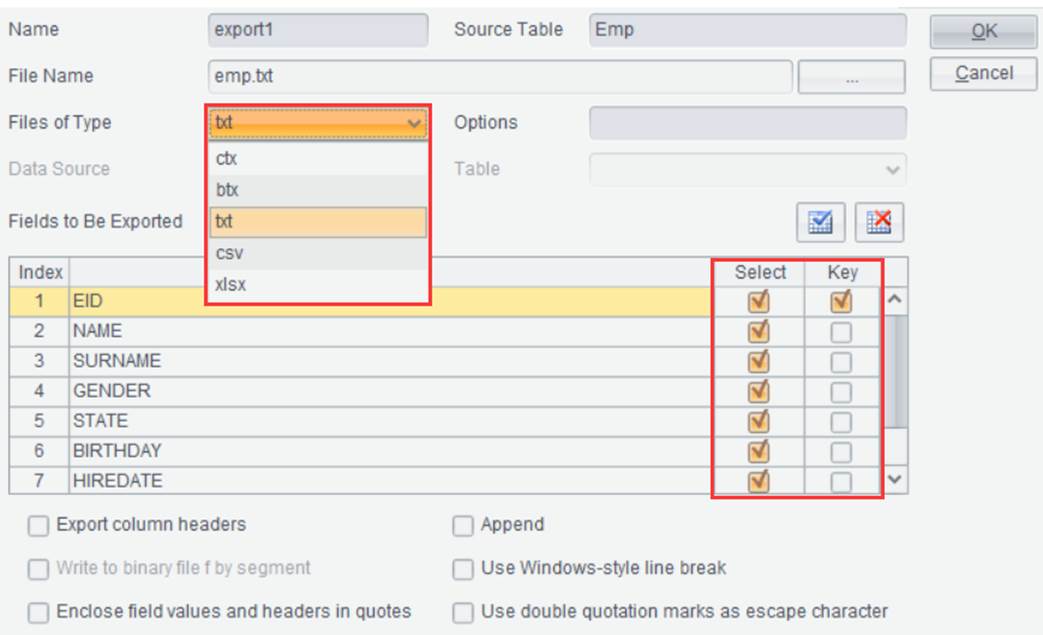
Set name of the file to be exported, select export type and options, check fields to be exported and the primary key, and click “OK” to export data in a result set to a file.
【Export column headers】 Write field names (titles) to the first row of the file.
【Append】Append-write; the appended contents need to have same data structure as the target file, otherwise error will be reported.
【Write to binary file by segment】 Write data as a faster binary file.
【Use Windows-style line break】Use Windows-style line break, which is \r\n; otherwise use system default.
【Enclose field values and headers in quotes】 Enclose exported text field values and names with quotes.
【Use double quotation marks as escape character】Convert two double quotation marks into one and do not escape other characters.