Group Cursor
For big data, besides data traversal and grouping and aggregation, sometimes a group of data with the same property needs to be retrieved each time for analysis, like analyzing sales data by date, plotting a sales curve for each product, and studying the purchase habit of each client.
7.9.1 Fetching data by group according to the expression
In esProc, you can use cs.fetch(;x) function or cs.skip(;x) function to get or skip a group of consecutive records depending on the value of expression x. For example, examining the sales information by retrieving the data of one product each time:
|
|
A |
B |
|
1 |
=file("Order_Wines.txt") |
|
|
2 |
=file("Order_Electronics.txt") |
|
|
3 |
=file("Order_Foods.txt") |
|
|
4 |
=file("Order_Books.txt") |
|
|
5 |
=[A1:A4].(~.cursor@t().sortx(PID)) |
|
|
6 |
=A5.mergex(PID) |
|
|
7 |
for 19 |
=A6.skip(;PID) |
|
8 |
=A6.fetch(;PID) |
|
|
9 |
>A6.close() |
|
The cursor in A6 contains the sales data of four kinds of products, which has been sorted by PID. From A8, records of the 20th product have been retrieved:
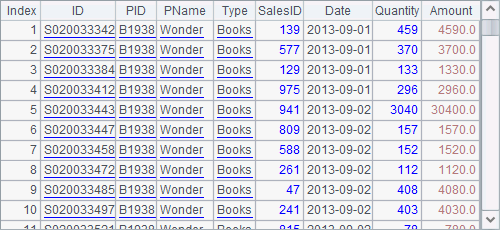
Note that the esProc traversal of cursor data is executed once in a forward-only direction. Therefore data in a cursor must be ordered as required when a group of records is retrieved each time.
7.9.2 Fetching data from file cursor by segment
The use of cs.fetch() is discussed in both Text Files and Bin Files. In addition, the file segmentation parameter can be used with the cursor or export function to retrieve data from a file or a cursor by segment (or by block). But sometimes problems arise during data fetching because of the way in which esProc segments a file.
Here’s an example. A data file is created to save the above data which is already sorted by PID as a new bin file Order_Products.btx:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t().sortx(PID)) |
|
6 |
=A5.mergex(PID) |
|
7 |
=file("Order_Products.btx") |
|
8 |
>A7.export@b(A6) |
Data is then retrieved by segment:
|
|
A |
|
1 |
=file("Order_Products.btx ") |
|
2 |
=A1.cursor@b(;1:100) |
|
3 |
=A2.fetch() |
|
4 |
=A1.cursor@b(;2:100) |
|
5 |
=A4.fetch() |
After data is divided into 100 segments, A3 retrieves the 1st segment and A5 retrieves the 2nd:
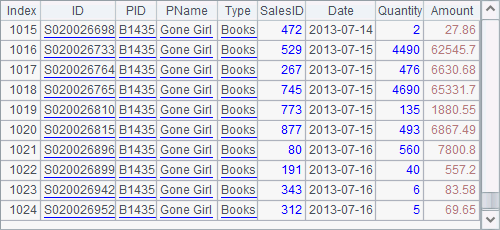
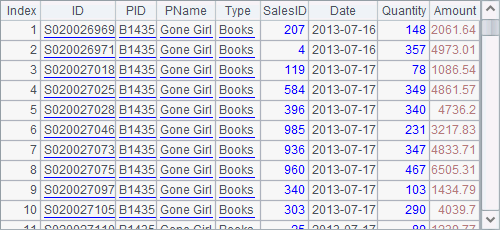
But a problem appears. For the product with the code number B1435, its sales records appear in both groups. If the aggregate operation is required after each data segment is fetched, then duplicate code numbers will appear in the returned result. Thus, re-aggregation will be needed to get the final result. Data segmentation is common during the parallel processing of big data, the problem makes the computation complicated. A solution is that data can be segmented by group by defining the grouping field when storing it in binary format.
When storing a bin file as a cursor, specifying the grouping field makes sure that the data is segmented by group while being exported. A set of records will be grouped together until the value of the grouping field is becomes different. Thus, data of a same group will be fetched all at once with segmental retrieval. For example:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t().sortx(PID)) |
|
6 |
=A5.mergex(PID) |
|
7 |
=file("Order_Products_G.btx ") |
|
8 |
>A7.export@b(A6;PID) |
Store the data that has been sorted by PID as a bin file Order_Products_G.btx and segment it by group according to PID. This is slightly different from the previous method for exporting data from the file Order_Products.btx. Note that the segmental storage is only valid when a segmentation field is specified for the storage. The field by which the original data is segmented into groups is specified in the function through a parameter at export. For example, A8 specifies that A6’s cursor is segmented by group according to PID, and in this case the cursor data must be ordered by the grouping field.
Now the result will be different if we fetch data by segment:
|
|
A |
|
1 |
=file("Order_Products_G.btx ") |
|
2 |
=A1.cursor@b(;1:100) |
|
3 |
=A2.fetch() |
|
4 |
=A1.cursor@b(;2:100) |
|
5 |
=A4.fetch() |
Generally, retrieving a bin file stored as a cursor is the same as reading an ordinary one. But since data is segmented by group when it is exported, the data fetching results become different, as shown this time by A3 and A5:
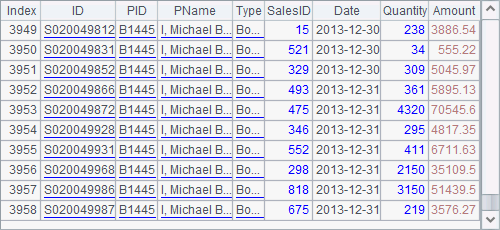

Sale records of the product whose ID is B1445 will all be fetched from segment one and segment two will be fetched starting from the next product ID. Thus, if the export() function specifies that a bin file is segmented by group when exporting it as a cursor, then the same group of data will be retrieved as a segment when the cursor is fetched out. Data segmentation by group guarantees data integrity in each segment, as well as makes the big data handling by segment simpler and easier.