Cursor-based Aggregate Operations
Besides batch retrieval with cs.fetch() function, a cursor also allows data grouping and aggregation performed directly on it.
7.3.1 Single-cursor grouping and aggregation
The commonest group and aggregate operations are counting and summation. In addition, there are other operations like finding maximum and minimum values and top-n data items. The cs.groups() function is used for a cursor-based data summarization, and various aggregate operations are carried out with count/sum/max/min/top/avg/iterate/icount/median functions. For example:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.mergex(Date) |
|
7 |
=A6.groups(Type;count(~):OrderCount,max(Amount):MaxAmount,sum(round(decimal(Amount),2)):Total) |
A7 summarizes data by product and calculates the total number of orders, the maximum transaction amount, and the total amount for each product. One thing to note is that the precision of the double-precision data is usually not enough. The decimal() function should thus be used to convert it to the big decimal type. In cursor-based group and aggregate operations, all records in the cursor will be traversed once. During the one traversal, a group operation involving each record and an aggregate of records in each group will be performed, and multiple types of aggregates can be handled. The cursor will automatically close once the traversal is completed.
Here’s A7’ result:
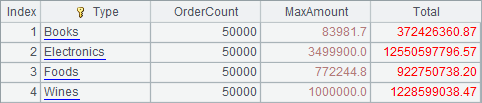
As can be seen from the result, there’re 50,000 records of orders for each product in the testing text data. Data of every file and the data of A6’s cursor are sorted by Date, but not sorted by Type. In both the original text files and A6’s cursor, data is ordered by Date but not by Type. But according to the use of the cs.groups() function in the example, it groups and aggregates data in a cursor without requiring the data to be ordered by the grouping value; it automatically sorts the result of grouping and aggregation by the grouping value instead. In addition, since cs.groups() returns a table sequence, the result set must not exceed the memory size when it groups and aggregates cursor data; it is not suitable for the cases where the result sets hold big data.
Finding top n is also one of the aggregate operations. To do that, use the aggregate function top:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.mergex(Date) |
|
7 |
=A6.groups(Type;top(3,Amount):MinAmount,top(3,-Amount):MaxAmount) |
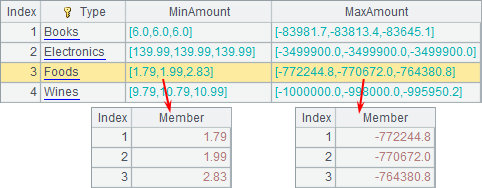
A7finds the bottom 3 order amounts with the minimum total and the top 3 order amounts with the maximum total based on the orders of each kind of product. Notice that a negative sign is added to the aggregate function when finding the top 3 order amounts, that is, top(3,-Amount). Here’s the result:
To aggregate all records, simply omit the grouping expression from cs.groups function:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.mergex(Date) |
|
7 |
=A6.groups(;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount) |
Now A7’s result is as follows:
![]()
The aggregate of all records can be regarded as a special grouping and aggregate operation.
7.3.2 Multi-cursor aggregation
When handling aggregate operations over multiple cursors, you can first compute the aggregate result for each cursor:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.(~.groups(Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount)) |
A6 groups and aggregates each file cursor separately to compute the daily aggregate value for each kind of product:
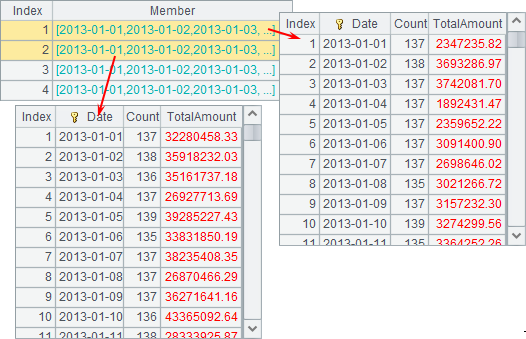
Because the cs.groups() function will sort cursor data by grouping value when performing grouping and aggregation, the resulting table sequence of aggregating each kind of product is always ordered by Date no matter what order in which the original data is arranged. Thus the result can be further merged to compute the daily aggregate value for all products:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.(~.groups(Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount)) |
|
7 |
=A6.merge(Date) |
|
8 |
=A7.groups(Date;sum(Count):Count,sum(round(decimal(TotalAmount),2)):TotalAmount) |
Here’s A8’s aggregate result:
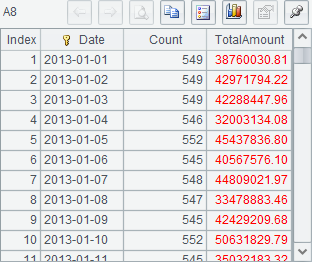
Since the data of each kind of product in every file has been sorted by Date, cursors can be first merged and then aggregated:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.mergex(Date) |
|
7 |
=A6.groups(Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount) |
As you can see, this method leads to the same result as that got in the above. For cursors in which data is ordered by the same value, it would be simpler and more effective to perform merge first, and then grouping and aggregation. Note the difference between merge and mergex. A.merge() merges the members of multiple sequences or records of multiple table sequences in a certain order, and returns a sequence. The computation is completed as the execution of the function finishes; while CS.mergex() merges the records of multiple cursors in a certain order, returns a cursor, and starts the computation when fetching data from the merged cursor. Both functions require that the data in sequence A and cursor CS is ordered. Detailed discussions about how to use mergex will be covered in Merge and Join Operations on Cursors.
7.3.3 Grouping and aggregation on big result sets
In the above section, each of multiple cursors is first grouped and aggregated to get a series of table sequences ordered by the same value, which then will be merged to get the final result. Similarly, you can deal with grouping and aggregation on big result sets.
The big result set means both the source data for computation and the result set are huge. The huge result set can’t be entirely read into the memory at once, but has to be retrieved step by step. Real-world business cases include the monthly bill of each customer issued by the telecommunication company and the sales of each product on a B2C website. The statistical data of both probably contain more than several millions of records.
esProc provides cs.groupx() function to perform grouping and aggregation over big result sets. Here we take the daily statistic on product orders as the example to illustrate the handling of big result sets. In order to get a more intuitive understanding about the memory limit, 100 records will be retrieved each time. In this case, the groupx function should be used to group and aggregate the daily orders:
|
|
A |
|
1 |
=file("Order_Wines.txt") |
|
2 |
=file("Order_Electronics.txt") |
|
3 |
=file("Order_Foods.txt") |
|
4 |
=file("Order_Books.txt") |
|
5 |
=[A1:A4].(~.cursor@t()) |
|
6 |
=A5.conjx() |
|
7 |
=A6.groupx(Date;count(~):Count,sum(round(decimal(Amount),2)):TotalAmount;100) |
|
8 |
=A7.fetch(100) |
|
9 |
=A7.fetch(100) |
|
10 |
=A7.fetch(100) |
|
11 |
=A7.fetch(100) |
A6 concatenates cursors in order without sorting them by Date. A7 groups and aggregates the joined cursor, and returns a cursor instead of a table sequence. Then A8~A11 retrieves data out step by step. Here’re their results:
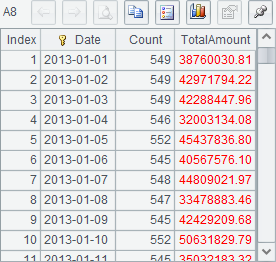
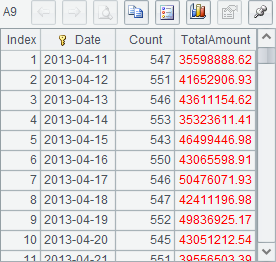
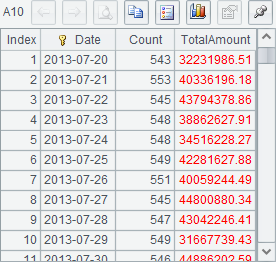
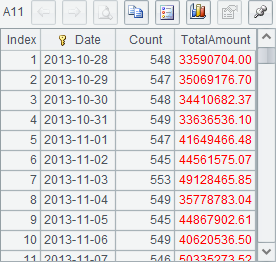
In which, each line of A8~A10 retrieves the statistical data of 100 days, and A11 retrieves the rest. After the data in A7’s cursor is completely fetched out, the cursor closes automatically.
A7 performs grouping and aggregation with groupx function while setting the number of buffer rows as 100. The last parameter in A7’s groupx function means that the memory can hold 100 records at most; thus data needs to be buffered when the number of records in the memory reaches 100. In real-time coding, the parameter isn’t needed because esProc will automatically estimate the number of records the available memory can hold to judge whether buffering should be performed or not. Thus, when executed, A7 fetches records from A6’s cursor and meanwhile, summarizes and aggregates them. Once the result of aggregating 100 records is produced, it will be buffered to a temporary file. The rest is done in the same manner. A7’s result is a cursor composed of a group of temporary files:
If the program is executed stepwise, these temporary files can be viewed in the system temporary directory after A7 is executed:
In order to know more about the contents of each of these bin files, you can retrieve data from them, for example:
|
|
A |
|
1 |
=file("temp/tmpdata1372633253707222252").import@b() |
|
2 |
=file("temp/tmpdata2669923936558108709").import@b() |
|
3 |
=file("temp/tmpdata3937021394605697131").import@b() |
|
4 |
=file("temp/tmpdata8767777617311441973").import@b() |
Below are results of A1 and A3:
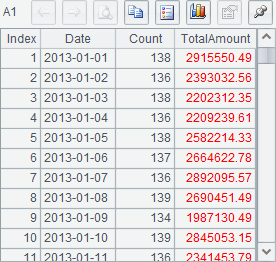
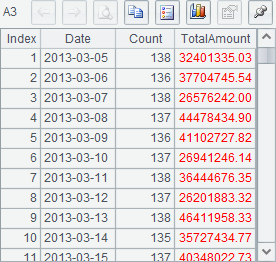
The names of these temporary files are generated randomly. Judging from the data retrieved from some temporary files, each temporary file stores the result of grouping and aggregating some consecutive original records, and sorts it by Date. In fact, according to the number of buffer rows specified in the function, each temporary file, except for the last one, contains the aggregate data of 100 days. For a cursor generated with groupx, its data will be fetched with fetch by merging all temporary files in a certain order.
After data is fetched out completely from a temporary file cursor or the cursor closes, the corresponding temporary file will be automatically deleted. About the external memory grouping, refer to Methods of External Memory Grouping for Large Result Sets.